A comunidade de prática de repositórios canadenses Canadian Association of Research Libraries CARL promoveu um Painel no dia 07 de maio de 2024 para apresentar questões e discutir a realidade das infraestruturas e as atividades realizadas em Repositórios institucionais, gerando o que foi denominado como “Um guia prático para infraestrutura aberta para gerentes de repositórios institucionais”
O objetivo do painel foi ajudar a preencher a lacuna entre o mundo mais amplo de infraestrutura, padrões e movimentos abertos (por exemplo, OpenAIRE, CORE, COAR e mais) e o trabalho diário de um gerente de repositório.
Os painelistas ajudaram a fornecer uma abordagem prática para questões como:
Se um dia eu perceber que tenho uma hora livre para trabalhar no sentido de alinhar melhor meu repositório com esses padrões e movimentos, qual é o primeiro passo que posso dar?
E se eu tiver uma semana inteira?
Ou talvez a oportunidade de realizar um projeto maior?
—
Este painel teve como objetivo começar a traçar um caminho desde onde quer que seu repositório esteja hoje até a participação em uma infraestrutura aberta mais ampla e o futuro da comunicação acadêmica.
Painelistas
Kathleen Shearer – Executive Director, Confederation of Open Access Repositories
Paul Walk – Owner and Director of Antleaf
Gabriela Mircea – Visiting Program Officer – OpenAIRE at CARL
Kyle Demes – Vice President, Research Intelligence at OurResearch (OpenAlex)
As bibliotecas são essenciais para o ecossistema Diamond Open Access
Participe da conversa em 30 de maio de 2024 e explore mecanismos de financiamento, desafios de sustentabilidade e muito mais. Cadastre-se aqui: https://ow.ly/VEIf50RH68j30 de maio. 2024 08:00 (BRT)
As bibliotecas são pilares vitais do ecossistema Diamond Open Access (OA), fornecendo infraestrutura, serviços e suporte especializado para editores institucionais. Muitas bibliotecas também são editoras por direito próprio. Para envolver as bibliotecas no avanço do Diamond OA na Europa, o projeto DIAMAS está a lançar uma Série de Conversas para bibliotecas.
Após uma breve visão geral das principais conclusões do nosso inquérito de 2023 sobre a publicação Diamond OA, a reunião centrar-se-á na questão premente da sustentabilidade financeira para os editores europeus de pequena e média dimensão e os seus prestadores de serviços.
Com base nos resultados de uma extensa pesquisa, lançaremos luz sobre as principais considerações de sustentabilidade e os desafios enfrentados por elas. Os participantes também obterão informações valiosas sobre os diversos mecanismos de financiamento que as editoras implementaram e sua viabilidade, enfatizando o papel indispensável da força de trabalho na sustentação da publicação Diamond OA.
Examinaremos também o impacto das infra-estruturas e dos serviços partilhados na viabilidade e continuidade dos serviços de publicação.
Esses insights servirão como catalisadores para uma discussão focada na experiência, nos desafios e nas necessidades de publicação da sua biblioteca acadêmica.
Ao longo da série exploraremos oportunidades para cocriar diretrizes, recomendações, recursos de defesa de direitos e ferramentas práticas.
Na primeira sessão, no dia 30 de maio, centramo-nos na partilha de recursos de advocacy e investigação sobre o panorama e a sustentabilidade do Diamond OA nas instituições de ensino superior europeias.
Cadastre-se agora para fazer parte desta conversa e nos ajudar a moldar o futuro do Diamond Open Access.
O Passport For Open Science é um guia concebido para acompanhar os estudantes de doutoramento em todas as etapas da sua carreira de investigação, qualquer que seja a sua área disciplinar. Fornece um conjunto de ferramentas e boas práticas que podem ser implementadas diretamente. Uma contribuição da organização Ouvrir la science. Esta é uma tradução livre do texto apresentado.
Preâmbulo
A ciência aberta nasceu das novas oportunidades que a revolução digital ofereceu para a partilha e divulgação de conteúdos científicos. Consiste essencialmente em tornar os resultados da pesquisa acessíveis a todos/as, eliminando quaisquer barreiras técnicas ou financeiras que possam dificultar o acesso às publicações científicas. Envolve também a abertura de “caixas pretas” dos pesquisadores contendo os dados e métodos utilizados pelas publicações para os partilhar tanto quanto possível.
Escolher a ciência aberta significa, antes de tudo, afirmar que a pesquisa que é financiada principalmente por fundos públicos deve comunicar os seus resultados ao público com o máximo de detalhe possível.
A abertura é uma condição necessária para a reprodutibilidade dos resultados científicos e para a garantia de pesquisas mais bem documentadas e fundamentadas. A partilha reforça a natureza cumulativa da ciência e incentiva o seu progresso.
A ciência aberta e transparente também ajuda a aumentar a credibilidade da pesquisa na sociedade e a crise sanitária de 2020 lembrou-nos, de fato, a importância desta questão. Por último, a ciência aberta é portadora de um movimento profundo no sentido da democratização do conhecimento em benefício das organizações, das empresas, dos cidadãos e, em particular, dos estudantes. para quem o fácil acesso ao conhecimento é condição de sucesso.
As políticas de ciência aberta têm agora apoio ao mais alto nível. São apoiadas pela União Europeia, que exige acesso aberto a publicações e dados para as pesquisas que financia e, desde 2021, define a ciência aberta como um critério de excelência científica.
As políticas de ciência aberta também são apoiadas mundialmente pelo G7 e pela UNESCO. Em França, o Primeiro Plano Nacional para a Ciência Aberta, lançado em 2018 pelo Ministério do Ensino Superior e da Investigação, foi reforçado por um segundo plano, em 2021, que afirma as suas ambições através de múltiplas iniciativas.
Todos os membros do ecossistema de pesquisa, através dos seus compromissos e práticas, incorporam e dão vida à ciência aberta. Ao começar a preparar o seu doutoramento – a última fase da sua formação e a primeira fase da sua vida profissional – junte-se ao movimento da ciência aberta e utilize este guia para iniciar uma conversa também dentro das suas redes de pesquisa.
O Passaporte para a Ciência Aberta é um guia concebido para acompanhá-lo/a em qualquer área de estudo, em todas as etapas da sua pesquisa, desde o desenvolvimento da sua abordagem científica até à divulgação dos resultados da sua investigação. Fornece um conjunto de ferramentas e melhores práticas que podem ser implementadas diretamente e destina-se a pesquisadores de todas as disciplinas.
Esperamos que este guia o/a motive e forneça os meios para concretizar as ambições da ciência aberta, partilhando os resultados e dados da sua investigação com o maior número de pessoas possível.
Marin Dacos Coordenador Nacional de Ciência Aberta Ministério Francês de Ensino Superior e Pesquisa
PLANEJANDO UMA ABORDAGEM ABERTA DE TRABALHO
Este guia aborda algumas das situações mais frequentes no dia a dia da pesquisa:
Planejando uma abordagem aberta ao trabalho científico Usando recursos de acesso gratuito Planejamento de gerenciamento de dados Planejamento de gerenciamento de software Trabalhar de forma rastreável e transparente: para si, para os outros
Divulgando pesquisas Divulgando suas publicações em acesso aberto Tornando sua tese acessível gratuitamente Tornando dados e software de pesquisa abertos
Preparando-se para depois da sua tese, junte-se ao movimento Políticas públicas profundamente enraizadas Avaliando a pesquisa de forma diferente
Durante Webinar que será realizado dia 23 de abril de 2024 será lançada oficialmente a Declaração de Barcelona sobre Informação Aberta de Pesquisa.
O panorama da informação em pesquisa requer mudanças fundamentais. Os signatários da Declaração de Barcelona sobre Informação Aberta para a Pesquisa comprometem-se a assumir a liderança na transformação da forma como ainformação de pesquisa é utilizada e produzida. A abertura de informações sobre a condução e a comunicação da pesquisa deve ser a nova norma.
A informação aberta sobre pesquisa permite que as decisões de política científica sejam tomadas com base em evidências transparentes e dados inclusivos. Permite que as informações utilizadas nas avaliações de investigação sejam acessíveis e auditáveis por aqueles que estão a ser avaliados. E permite que o movimento global em direção à ciência aberta seja apoiado por informações totalmente abertas e transparentes.
Definição de informações de pesquisa Por informações de pesquisa entendemos informações (às vezes chamadas de metadados) relacionadas à condução e comunicação da pesquisa. Isso inclui, mas não está limitado a, (1) metadados bibliográficos, como títulos, resumos, referências, dados de autores, dados de afiliação e dados sobre locais de publicação, (2) metadados sobre software de pesquisa, dados de pesquisa, amostras e instrumentos, (3) informações sobre financiamento e subsídios e (4) informações sobre organizações e contribuidores de pesquisa. As informações de pesquisa estão localizadas em sistemas como bancos de dados bibliográficos, arquivos de software, repositórios de dados e sistemas de informação de pesquisa atuais.
Para este fim, os signatários, como organizações que realizam, financiamos e avaliamos pesquisas, nos comprometemos a:
COMPROMISSOS
1 Faremos da abertura o padrão para as informações de pesquisa que usamos e produzimos
2 Trabalharemos com serviços e sistemas que apoiem e possibilitem informações abertas de pesquisa
3 Apoiaremos a sustentabilidade das infraestruturas de informação aberta para a investigação
4 Apoiaremos ações coletivas para acelerar a transição para a abertura da informação sobre pesquisa
Para atingir o ponto de virada na transição de informação fechada de pesquisa para informação de aberta de pesquisa, é necessária uma ação mais concertada. Apelamos, portanto, a todas as organizações que realizam, financiam e avaliam investigação para apoiarem a transição para informação de investigação aberta e para assinarem a Declaração de Barcelona sobre Informação Aberta de Pesquisa. Sobre A Declaração de Barcelona sobre Informação Aberta de Pesquisa foi preparada por um grupo de mais de 25 especialistas em informação de investigação, representando organizações que realizam, financiam e avaliam investigação, bem como organizações que fornecem infraestruturas de informação de pesquisa.
O grupo reuniu-se em Barcelona em novembro de 2023 num workshop organizado pela Fundação SIRIS. A preparação da Declaração foi coordenada por Bianca Kramer (Sesame Open Science), Cameron Neylon (Curtin Open Knowledge Initiative, Curtin University) e Ludo Waltman (Centro de Estudos de Ciência e Tecnologia, Universidade de Leiden).
Webinar Oficial de Lançamento
O webinar oficial de lançamento da Declaração de Barcelona acontecerá no dia 23 de abril, das 13h00 às 14h30 CEST, ao qual convidamos você a participar. Cliqueaqui para se inscrever no webinar. O webinar será em inglês.
Para proporcionar os benefícios da ciência aberta, aumentar a adoção de práticas de ciência aberta é um pré-requisito. Essas práticas incluem dados de pesquisa, compartilhamento de protocolos e códigos, publicação de pré-impressão e publicação em acesso aberto.
Existem inúmeras iniciativas em todo o ecossistema de investigação – políticas, formação, ferramentas, incentivos – de financiadores, investigadores, instituições e editores que deverão levar a uma maior adoção de práticas de ciência aberta.
Participe deste Simpósio Virtual Medindo a Ciência Aberta para saber mais!
Exemplos de iniciativas incluem as Redes Internacionais de Reprodutibilidade lideradas por pesquisadores para promover práticas de pesquisa aberta, alinhando a ciência através dos rigorosos requisitos de ciência aberta de Parkinson e a mudança da eLife em direção a um modelo de publicação pré-impresso.
Mas faltam-nos evidências abrangentes e fiáveis sobre a forma como as práticas de ciência aberta estão a ser amplamente adotadas pelos investigadores e como essas práticas variam entre disciplinas e geografias (comunidades).
Surgiram outras iniciativas que abordam este problema de medir o progresso em direção à ciência aberta. Isso inclui o trabalho de meta-pesquisadores, como o Charite Metrics Dashboard do BIH QUEST, e ferramentas como DataSeer e SciScore.
A editora PLOS também introduziu ‘Indicadores de Ciência Aberta‘ (OSI) para rastrear a adoção de práticas de ciência aberta ao longo do tempo na literatura acadêmica.
Com toda esta atividade que partilha um objetivo comum de aumentar a adoção da ciência aberta, há necessidade de conversas sobre como definimos e medimos diferentes práticas de ciência aberta, para que fins e para que públicos e consideramos as diferenças específicas do campo.
Este simpósio virtual reunirá investigadores, financiadores, instituições e representantes de editores para apresentar desenvolvimentos nesta área e explorar pontos em comum e diferenças em abordagens, o que poderá promover futuras colaborações.
Inspirados pelo feedback da comunidade de usuários, temos o prazer de anunciar a primeira Conferência Virtual de Usuários OpenAlex!
Com base em quase 200 respostas à nossa pesquisa de planejamento, serão realizados dois eventos diferentes no final de maio. Agenda e mais detalhes em breve, mas reserve a data agora para o horário que for melhor para você.
– Quinta-feira, 30 de maio [12h – 16h EST]
– Sexta-feira, 31 de maio [10h – 14h CET]
Ambos os eventos contarão com apresentações de usuários OpenAlex de todo o mundo com perguntas e respostas ao vivo e apresentações gravadas que estarão disponíveis para visualização posteriormente.
Procuramos usuários do OpenAlex para fazer apresentações curtas (12 minutos) mostrando as diversas maneiras como estão usando o OpenAlex. Informe-nos através deste formulário até 29 de abril de 2024.
Fique atento para uma agenda detalhada no início de maio.
Se você tiver alguma dúvida ou feedback enquanto planejamos o evento, envie uma mensagem para support@openalex.org
A Fiocruz realiza a Conferência Livre “Acesso Aberto: Possibilidades e Limites dos Acordos Transformativos e APCs” nos dias 9 e 10 de abril com objetivo de debater as atuais tendências e disputas ao redor deste movimento internacional e influenciar as definições da próxima Estratégia Nacional Ciência, Tecnologia e Inovação (ENCTI) 2024-2030.
A Conferência Livre conta com dois eventos.
No primeiro dia, 9 de abril, das 9h às 12h, o Museu da Vida recebe o debate “Acesso Aberto: Possibilidades e Limites dos Acordos Transformativos”. O evento, organizado em parceria pela Vice-Presidência de Educação, Informação e Comunicação (VPEIC) e o Instituto de Comunicação e Informação Científica e Tecnológica em Saúde (Icict), acontece no Museu da Vida, das 9h às 12h, e conta com transmissão ao vivo pelo canal VídeoSaúde no YouTube.
Já no segundo dia, 10 de abril, o Núcleo de Ciência Aberta da Escola Nacional de Saúde Pública Sérgio Arouca (ENSP) promove a mesa de debates “O Mercado da Publicação Científica e a Plataformização da Ciência: Riscos e Desafios”. O evento acontece no prédio da ENSP, sala 410, das 14h às 17h e conta com transmissão pelo canal da ENSP no YouTube.
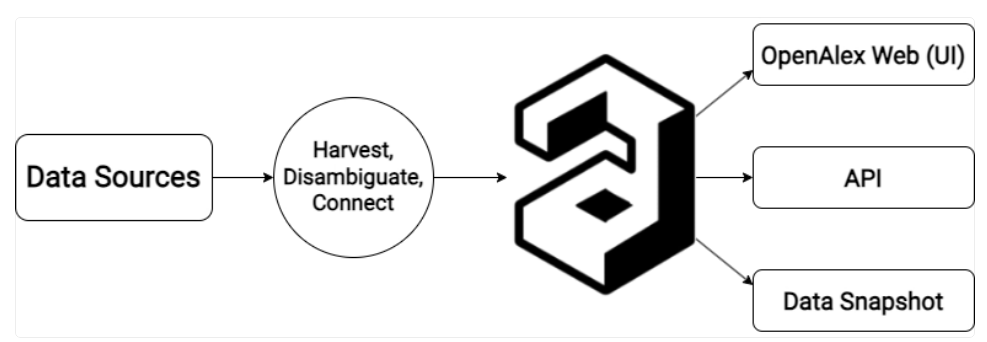
OpenAlex é uma base de dados bibliográfica totalmente aberta que indexa cerca de 250 milhões de trabalhos científicos, 90 milhões de autores, 100.000 instituições e 32.000 financiadores (dados de dezembro de 2023). Tem esse nome em referência à antiga Biblioteca de Alexandria.
OpenAlex depende de dados e infraestruturas abertas (notadamente Crossref, RoR, ORCID, DOAJ e Wikidata) e tecnologias avançadas como computação em nuvem e aprendizado de máquina para fornecer um gráfico de conhecimento acadêmico ligando publicações, seus autores, afiliações e financiamento, com metadados enriquecidos.
Todos os dados fornecidos pelo OpenAlex são abertos a todos, sem necessidade de registro e sob uma licença aberta que permite reutilização e modificação (licença CC0). OpenAlex é uma iniciativa recente, que está progredindo rapidamente na qualidade e riqueza da informação que oferece, graças, em particular, à sua abertura às contribuições da comunidade de pesquisa.
Como funciona
OpenAlex é mais do que apenas um catálogo de publicações de pesquisa. É feito um trabalho de desambiguação e conexão de trabalhos acadêmicos, autores, instituições, fontes e outras entidades. Em seguida, os dados e análises são oferecidos a partir de três canais diferentes, dependendo de suas necessidades:
API OpenAlex — Uma API REST rápida e moderna para obter os dados programaticamente
Instantâneo de dados — Um instantâneo periódico dos dados, disponível para download na íntegra, gratuitamente
Visão geral de dados
No coração do OpenAlex está nosso conjunto de dados – um catálogo de trabalhos . Uma obra é qualquer tipo de produção acadêmica. Um artigo de pesquisa é um tipo de trabalho, mas existem outros, como conjuntos de dados, livros e dissertações. Acompanhamos esses trabalhos – seus títulos (e resumos e texto completo em muitos casos), quando foram criados, etc. Mas não é só isso que fazemos. Também acompanhamos as conexões entre esses trabalhos, encontrando associações por meio de itens como periódicos , autores , afiliações institucionais , citações, conceitos e financiadores .
Existem centenas de milhões de trabalhos por aí e dezenas de milhares de outros sendo criados todos os dias, por isso é importante que tenhamos estas relações para nos ajudar a dar sentido à investigação em grande escala.
OpenAlex agrega e padroniza dados de vários outros grandes projetos, como um rio alimentado por muitos afluentes. Nossas duas fontes de dados mais importantes são MAG e Crossref. Outras fontes chave incluem:
O site, a API e o instantâneo de dados estão disponíveis gratuitamente. Os dados são licenciados como CC0 , portanto seu uso e distribuição são gratuitos. Como organização sem fins lucrativos, tornar esses dados gratuitos e abertos faz parte da missão do OpenAlex.
Ser sustentável também faz parte dessa missão! A sustentabilidade depende das receitas provenientes de duas ofertas de valor agregado: assinantes pagos e serviços de consultoria.
Tutorial
Você pode começar a usar, explorar, baixar, compartilhar e analisar o OpenAlex imediatamente usando a caixa de pesquisa em openalex.org .
Para começar a usar a API ou o instantâneo completo dos dados, consulte a documentação técnica .
Para um vídeo passo a passo da interface da web, clique em Reproduzir abaixo:
Com direção de publicação do Ministério Francês de Ensino Superior e Pesquisa, coordenação editorial da Universidade de Lille e apoio do Conselho científico: The Skills and Training College of The Committee for Open Science, acaba de ser publicado o e-book Open Science Research Data (Février 2024). Esta é uma tradução livre do texto.
Derivado do Passport for Open Science, um guia concebido para acompanhar os estudantes de doutoramento em todas as etapas da sua carreira de pesquisa, qualquer que seja a sua área disciplinar, o presente guia Open Science Research Data (Février 2024) fornece um conjunto de ferramentas e boas práticas que podem ser implementadas diretamente, bem como aborda os principais conceitos envolvidos na gestão e divulgação de dados de pesquisa.
Como parte da coleção Passaporte Francês para a Ciência Aberta, este guia cobre os principais conceitos envolvidos na gestão e divulgação de dados de pesquisa. Uma contribuição da organização Ouvrir la science.
Destina-se a pesquisadores como você, seja qual for a sua disciplina! À medida que você lê, você encontrará explicações sobre o que são os dados de pesquisa, as questões envolvidas em gerenciá-los com sabedoria e os benefícios de compartilhá-los, bem como a melhor forma de receber suporte para gerenciá-los e compartilhá-los.
Tudo que você precisa saber sobre dados de pesquisa
Existem muitas definições, mas a mais comumente usado é a da Organização para Cooperação Econômica e Desenvolvimento (OCDE), que define dados de pesquisa como: “registros factuais (pontuações numéricas, registros textuais, imagens e sons) usados como fontes primárias para pesquisa científica, e que são comumente aceito na comunidade científica conforme necessário para validar a pesquisa descobertas”.
VALE A PENA SABER O código-fonte e o software não devem ser considerados como dados. Eles vêm com especificações desafios, práticas e recomendações quando se trata de compartilhamento e abertura. Consulte o livreto intitulado ▼Código-fonte e software.
Os dados da pesquisa podem ser caracterizado com base no seguinte:
Como foram obtidos: dados produzidos como parte de experimentos ou análises utilizando instrumentos, observação dados, dados coletados durante uma pesquisa ou amostragem de campo, etc. Você também pode produzir seus próprios dados ou reutilize dados produzido em outro lugar.
Tipo: textual, audiovisual, digital, de imagem, de observação, de genômica sequenciamento, etc. produzido usando determinada medição, análise ou instrumentos de observação
Formato: dados em formato aberto ou proprietário formatar.
Contexto de produção: industrial parceria, laboratório em zona de acesso restrito, etc.
Regime jurídico: dados pessoais (Regulamento Geral de Proteção de Dados), abrangido por sigilo (por exemplo, profissional, defesa ou industrial), sujeito a um acordo de confidencialidade, obrigações contratuais (contrato que rege o acesso), etc.
Natureza crítica: sensível, confidencial, etc.
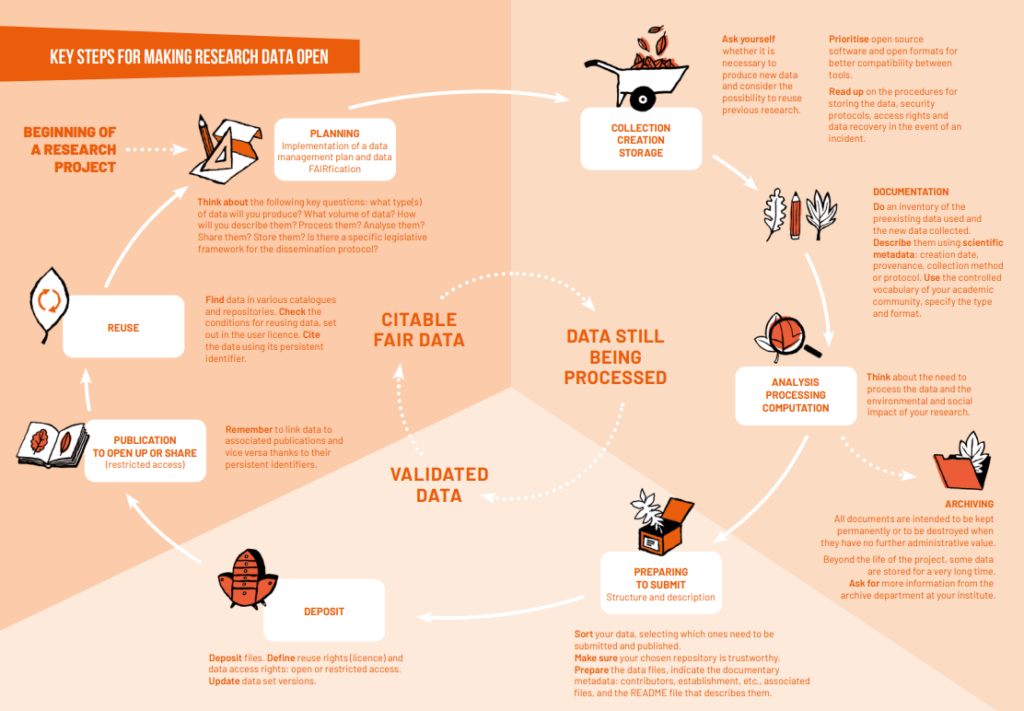
Principais etapas para tornar os dados da pesquisa abertos
Ao longo de um projeto de pesquisa, os dados são coletados, gerados ou reutilizados e depois armazenados para que possam ser processados e analisados. Eles serão então estruturados, limpos e classificados de modo que apenas os dados relevantes para divulgação ou publicação sejam mantidas sempre que possível em um repositório de dados.
Além disso, alguns dados, especialmente observações feitas ao longo do tempo, também são arquivados para armazenamento de longo prazo.
Essas diferentes etapas pontuam o projeto de pesquisa e inventam o que é chamado de ciclo de vida dos dados. O gerenciamento de dados deve torná-los localizáveis, acessíveis, compreensíveis para humanos e máquinas, ou seja, interoperáveis e reutilizáveis.
Isso é o que conhecemos como princípios FAIR. Eles cobrem as diferentes maneiras pelas quais os dados de pesquisa são construídos, armazenados, apresentados, compartilhados e reutilizados.
O desafio que sustenta a A FAIRificação dos dados de pesquisa visa, em última análise, garantir que eles possam ser reutilizados pela equipe que os produziu, bem como por outros e diretamente por máquinas para alimentar futuras pesquisas, meta-análises e modelos em grande escala (clima, biodiversidade, pandemias, aprendizado de máquina, etc.).
A importância dos Metadados
Todas essas noções são usadas para descrever dados e inventar o que chamar metadados.
Metadados científicos fornecem informações sobre os dados, em particular: protocolo e contexto em que foram obtidos, referências de tempo, configurações dos instrumentos utilizados, ferramentas e software de análise, etc. , usando o vocabulário controlado do campo de pesquisa.
Metadados documentais fornecem informações mais específicas informações sobre coisas como instituição e as pessoas que produziram os dados, condições de uso e acesso, identificador persistente de conjunto de dados, o identificador das publicações e o código do software vinculado aos dados, etc.
POR QUE DIVULGAR DADOS?
Compartilhar e abrir dados de pesquisa facilita sua reutilização por você e outros, sejam membros da equipe de seu projeto ou equipe de pesquisa, ou o comunidade científica como um todo.
Divulgar seus dados ajuda a aumentar a visibilidade do seu trabalho e permite que você seja mais citado. Segundo estudo publicado na revista PLOS ONEs, artigos científicos com dados abertos foram citados 25% a mais.
A divulgação de dados de pesquisa contribui para a transparência do abordagem científica e aumenta o nível de confiança na ciência entre os cidadãos.
Também contribui para a reprodutibilidade da ciência, esclarece a forma como os dados foram produzidos, analisados e processados e constitui, assim, um forte marcador de integridade científica e ética.
Também vale a pena divulgar dados que não levaram a uma publicação ou resolução de uma hipótese científica inicial. Tais dados podem ser úteis para outros pesquisadores na exploração de novas hipóteses, na condução de novas pesquisas, inclusive em outros campos ou destacando resultados negativos.
VALE A PENA SABER
O setor digital está desfrutando de um forte crescimento. Esse setor é um consumidor de recursos abióticos responsável por múltiplas formas de poluição e, através do seu impacto no ambiente e na sociedade, exacerba a pressão exercida sobre os limites do nosso planeta.
Os dados de pesquisa digital fazem parte deste crescimento e, para evitar o aumento da sua pegada ambiental dos produtos e serviços digitais, é essencial:
1) permitir a reutilização (princípios FAIR) de dados existentes antes de tentar produzir novos dados, e
2) documentar com o máximo de detalhes e clareza possíveis o uso e o impacto dos seus dados. Para alinhar a ciência aberta com os objetivos ambientais, é crucial tornar os seus dados encontráveis e acessíveis, mas também para destruir quaisquer dados que não serão mais úteis porque não foram descrito adequadamente.
Estas práticas são recomendadas quando se trata de compartilhamento e destruição de dados redundantes e são uma forma de reduzir a pegada digital dos dados.
A coleta e análise de dados são fases muito dispendiosas.
Dados que nem são compartilhados nem disseminados são, portanto, uma perda para a equipe de pesquisa. O relatório da Comissão Europeia, Custo de não ter dados de pesquisa FAIR lançado em 2019, estima o custo da má gestão de dados de pesquisa em 3 mil milhões de euros para França, devido ao tempo perdido, custos de armazenamento não otimizados, custos de licença e problemas de duplicação de pesquisa.
Alguns dados de pesquisa são únicos. Esse é a verdade para dados de longo prazo que monitoram parâmetros ambientais, por exemplo. Esses dados estão em arquivos públicos, de acordo com a Lei do Patrimônio (Código du Patrimoine em francês) e, portanto, fazem parte do nosso sistema científico, nossa herança nacional. Usando descrições precisas, compartilhando e garantindo o abertura dos dados observacionais de campo, é possível constituir séries temporais e realizar análises ao longo várias décadas, por exemplo para avaliar o impacto das alterações climáticas.
A divulgação de dados está incluída nas recomendações no âmbito do Plano Nacional Francês. É também uma forma de respeitar tanto as obrigações de legislação e as demandas dos financiadores bem como certos periódicos.
COMO DIVULGAR DADOS?
Preparando-se para a divulgação de dados.
Planeje seu gerenciamento de dados. A divulgação de dados deve ser preparada no início do projeto de pesquisa. Para conseguir isso, um plano de gerenciamento de dados, ou DMP, é uma ferramenta que irá permitir que você descreva como os dados serão gerenciados, armazenados, analisados e preservados, antecipando a forma como serão abertos, o que está sujeito às disposições legais e estruturas contratuais etc. relevantes para os dados do projeto.
O DMP evolui ao longo do tempo e deve ser adaptado a cada fase do projeto de pesquisa. O DMP vem na forma de um documento dividido em seções baseadas em um modelo frequentemente recomendado ou mesmo em seções impostas pelo órgão fiscalizador ou agência financiadora. Você encontrará modelos em ▼DMP Tool.
Seu objetivo é fornecer uma visão geral da descrição e evolução dos conjuntos de dados no projeto de pesquisa. Ele descreve os dados e como eles são gerenciados durante o projeto e define os procedimentos para sua disseminação, reutilização e preservação. É ainda mais importante mantê-lo atualizado, pois é um documento de orientação de gerenciamento de dados durante todo o projeto e além.
Os vários modelos DMP recomendam seguir os princípios FAIR e são geralmente estruturados em torno deles. Isso permite antecipar onde e como seus dados serão divulgados e sob quais condições.
A USP tornou-se instituição filiada à dmptool.org, uma organização que disponibiliza a ferramenta DMPTool ▼https://dmptool.org/ para elaborar Planos de Gestão de Dados (PGD) de forma rápida e prática. A STI configurou esta ferramenta para que pesquisadores da USP possam responder (em Língua Portuguesa ou Inglesa) perguntas cujas respostas compõem um PGD.
Protocolos para o divulgação de dados pessoais
Dados contendo informações pessoais podem ser tornados públicos depois de terem sido processado usando codificação, anonimização ou pseudonimização, dependendo sobre o nível de confidencialidade e o natureza dos dados tratados. O nível de confidencialidade deve ser determinado em colaboração com sua organização e os objetivos do seu projeto de pesquisa.
• O anonimato torna isso definitivo impossível identificar a pessoa. ▼Amnésia é uma ferramenta que permitirá que você anonimizar seus conjuntos de dados.
• A pseudonimização impede outras pessoas de identificar um indivíduo sem usando dados de terceiros. Ao contrário da anonimização, a pseudonimização é reversível. Envolve a substituição de identificadores (sobrenome, nome, etc.) por identificadores indiretos (alias, número, etc.). Dados totalmente anonimizados não vão mais conter informações pessoais e podem, portanto, ser abertos.
QUAL É O PRÓXIMO PASSO? PREPARANDO PARA O FUTURO
Promover seus dados. Além de submeter os seus dados a um repositório, você pode optar por promove-los em um documento de dados. Este documento pode ser um artigo que descreve um conjunto de dados original, visando à sua reutilização.
Ele contém um descrição detalhada do conjunto de dados (contexto de produção, produtores, direitos associados, etc.), bem como o acesso a ele, muitas vezes na forma de um vínculo persistente com o repositório de dados.
Os artigos de dados seguem o mesmo processo editorial de revisão de artigos. Há diferentes periódicos que publicam artigos de dados. Eles podem ser multidisciplinares, disciplinares ou temáticos. O ▼CoopIST fornece pontos-chave para a compreensão sobre como estruturar o conteúdo de um dado artigo, como escolher um periódico adequado para a publicação de seus dados.
Você encontrará diferentes critérios e exemplos de revistas de dados para cada disciplina. Vinculando seus dados usando um identificador persistente, as citações tornam-se mais fáceis e estáveis, uma vez que este tipo de identificador fornece um único caminho para o conjunto de dados. Em uma publicação, os dados associados, autores e colaboradores estarão inequivocamente vinculados a longo prazo e com estabilidade graças para o identificador persistente, independentemente da forma da informação utilizada para descrevê-los nas diferentes instituições.
A ▼DataCite é uma organização sem fins lucrativos que atribui identificadores de conjunto de dados em um nível internacional. A agência francesa responsável por atribuir DOIs aos dados, DataCite França, é administrado pelo Inist-CNRS. A provisão de certos persistentes identificadores faz parte de serviços complementares, como o automatizado formatação de citações, possibilitada por identificadores de objetos digitais. O DOI é atribuído automaticamente pelo repositório no qual os dados são mantidos.
Licenças
Ao publicar dados, é altamente recomendado associá-los a um licença para definir como podem ser reutilizados e modificados. Na França, um decreto lista as licenças que as administrações podem utilizar para divulgar dados públicos. As licenças ▼Etalab proporcionam aos produtores e reutilizadores dos dados em questão a necessária segurança jurídica, autorizando sua reprodução, redistribuição, adaptação e exploração comercial ao mesmo tempo em que torna obrigatória a citação de seus proveniência.
Além da licença Etalab, nós também recomendamos adicionar o ▼Licenças Creative Commons. Isso permite que você para personalizar o grau de abertura você deseja e com a licença CC-BY, para creditar os produtores dos conjuntos de dados. Uma lista de licenças geralmente é proposta pelo repositório de dados que será responsável pelo armazenamento e divulgação dos dados submetidos.
Questões práticas sobre Colaboradores da Equipe
Ao longo do ciclo de vida dos dados, diferentes as pessoas contribuem para a sua abertura: o pesquisador que considera quais dados para abrir ao redigir o manejo do plano de dados, os profissionais que apoiam o processo de pesquisa e acompanham as diferentes fases da gestão dos dados, o encarregado da proteção de dados que aconselha o pesquisador sobre as condições em que os dados pessoais podem ser abertos, o supervisor científico do projeto que envia os dados para um repositório para que possam ser reutilizados, e finalmente, os editores de documentos de dados. Para reconhecer adequadamente esses vários colaboradores ao divulgar seu resultados, você pode consultar ▼CRedit, uma taxonomia que identifica até 14 funções diferentes dentro de um projeto de pesquisa.
Escolhendo um repositório de dados
Escolher seu repositório de dados é crucial porque nem todos são igualmente compatíveis com os princípios FAIR. Para que os dados sejam facilmente acessíveis, eles devem ser disponibilizados em um repositório. Para que os dados sejam Localizáveis, eles também devem ser referenciados em catálogos ou em plataformas usando um identificador persistente. Ao publicar um conjunto de dados, o repositório atribuirá a ele um único identificador persistente. Quanto mais dados forem descritos usando recursos ricos e metadados detalhados (título, produtores, data, resumo, formato, identificador persistente, condições de acesso e utilização, metadados geográficos e temporais, etc.), melhor eles serão indexados e, portanto, serão mais fáceis de encontrar.
Para atender aos objetivos de qualidade dos dados, alguns repositórios moderam os dados antes que eles sejam publicados e sugerem ao depositante formas de melhorar a descrição dos seus conjuntos de dados com base em critérios claramente definidos estabelecidos em um guia de curadoria.
Para maior visibilidade, compartilhamento e reutilização dos dados produzidos ou coletados como parte dos projetos científicos, há uma oferta diversificada de repositórios de dados: temáticos ou disciplinares, focados na confiança ou certificação, institucional ou soberana, generalista, etc
As plataformas ▼re3data.org e ▼FAIRsharing.org permitem verificar diversos repositórios. Para identificar aquele que melhor se adapta a você, é útil saber mais sobre cada um modelo de negócios, funções e características, para certificar-se de que atenderá às suas necessidades científicas, documentais e técnicas (área disciplinar, tipo de dados aceitos, volume limitado).
• atribuir sistematicamente uma persistente identificador para dados e/ou conjuntos de dados,
• sugerir dados padronizados e abertos estrutura de descrição,
• estabelecer as condições de acesso e o quadro para a reutilização através do concessão de licenças,
• garantir um certo nível de preservação e acessibilidade a longo prazo para tanto os dados quanto os metadados por meio do implementação de uma política específica e governação.
Existem outras perguntas que você deve fazer ao escolher um repositório confiável:
• Existe um repositório usado por pares em sua área de pesquisa?
• O repositório atende aos requisitos nacionais objetivos da política de ciência aberta e satisfaz as diretrizes estabelecidas na FAIR princípios?
• Será atribuído um identificador persistente para seus dados?
• Por quanto tempo os dados serão armazenados?
• Que tipo de moderação utiliza?
• Oferece a possibilidade de um embargo?
• É recomendado pelo financiamento agências?
• O repositório é certificado?
ATENÇÃO
Enviar dados para um repositório não significa que eles serão mantidos por muito tempo. Por isso é importante distinguir entre armazenar, salvar e arquivar dados.
Armazenamento significa simplesmente que os dados são mantidos digitalmente durante a duração do projeto, enquanto o objetivo de salvar dados é duplicá-los em vários dispositivos digitais. O
arquivamento é um processo que ao final do projeto permite conservar dados por muito tempo. Todos os repositórios de dados divulgam dados, mas apenas alguns deles oferecer serviços de arquivamento de dados em parceria com organizações como ▼ Quetelet-Progedo
Considerações finais
O movimento Ciência Aberta visa construir um ecossistema em que a ciência seja mais cumulativa, mais apoiada em dados, mais transparente, mais rápida e proporcione acesso universal (OUVRIR LA SCIENCE)
Desde que pesquisadores, universidades, agências de financiamento e publishers começaram a promover o acesso aberto, muita coisa mudou no cenário da publicação científica, desde a avaliação de pesquisa majoritariamente baseada em produtividade e impacto de publicações até os lucros cada vez maiores das grandes editoras científicas.
Introdução
O custo crescente das taxas de publicação (APC: taxa de processamento de artigos paga pelos autores ou pelos seus empregadores) representa um sério desafio à manutenção do modelo de acesso aberto, mantendo ao mesmo tempo um ecossistema saudável para partilhar livremente todas as publicações científicas e bases de dados.
Na 46ª Reunião Anual da Sociedade de Biologia Molecular do Japão (MBSJ) em Kobe, Japão, a MBSJ e a EMBO Press co-organizaram um seminário intitulado “Encontrando um lar feliz para o seu artigo: discussão sobre publicação de pesquisas e ciência aberta” . Neste seminário, Masanori Arita, autora de “The Road of Scientific Publishing”, resumiu o estado atual e as questões da publicação científica.
Isto foi seguido por um painel de discussão com Bernd Pulverer, editor-chefe do EMBO Reports , Tadashi Uemura, membros do conselho do jornal oficial do MBSJ, Genes to Cells , e Shigeo Hayashi, presidente da 46ª reunião anual do MBSJ. Chisako Sakuma, membro do MBSJ, moderou o seminário.
Este artigo resume questões e ideias dos palestrantes e do público para superar os desafios do compartilhamento gratuito de dados e discutir o futuro da ciência aberta.
No modelo atual, o acesso aberto é insustentável
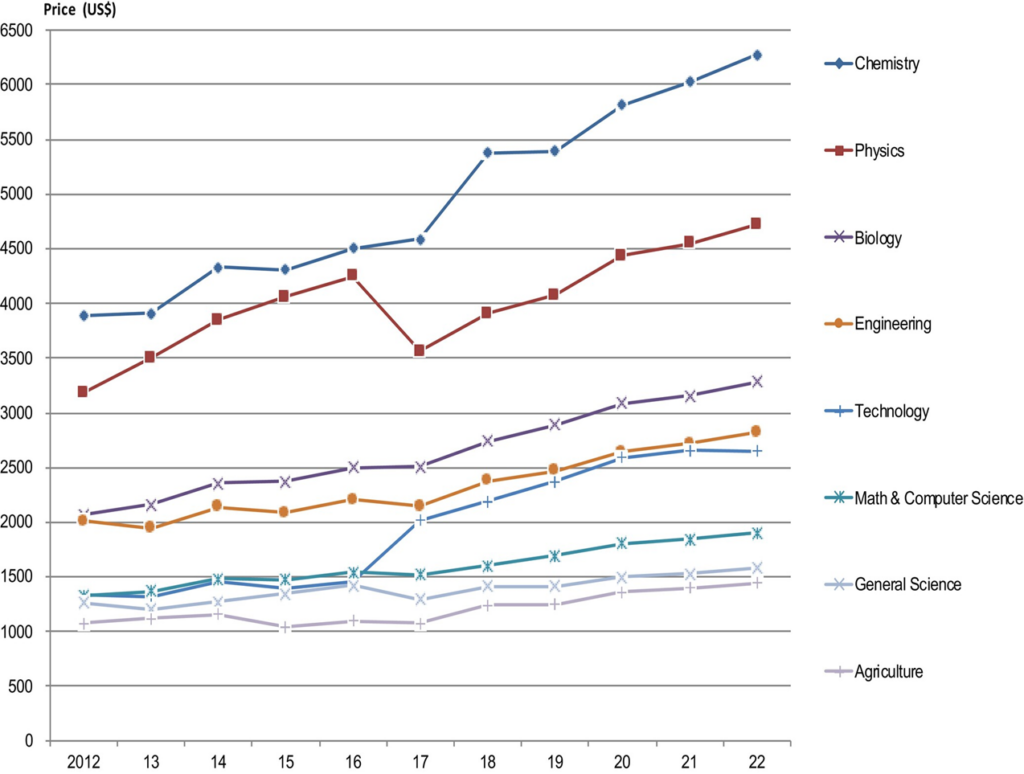
No Quadro 1 é possível observar a tendência das taxas de assinatura de periódicos eletrônicos de 2012 a 2022 (US$). O aumento médio na categoria Biologia é de 4,71% ao ano.
Considerando o cenário financeiro das universidades japonesas e a maioria das bibliotecas universitárias ao redor do mundo, o estilo tradicional de partilha de dados de pesquisa por meio da publicação em revistas baseadas em assinaturas está difícil de sustentar.
Revistas de Acesso Aberto são muito lucrativas (para as grandes editoras)
Ciência Aberta é um movimento que visa compartilhar publicações e dados de pesquisa acessíveis gratuitamente a todos. Um aspecto em rápida expansão da Ciência Aberta é o modelo de publicação de acesso aberto (Open Acess) pago pelo autor.
Quando a PLoS One começou a publicar artigos em 2006 condicionados apenas pela solidez científica, muitos pesquisadores acolheram seu serviço e pagaram alegremente a taxa de processamento de artigos (APC) de US$ 1.250 (US$ 1.931 em 2023). A revista logo se tornou a maior e mais lucrativa em publicação científica, técnica e médica (STM).
O sucesso de “PLoS ONE” levou muitas editoras comerciais tradicionais, bem como editoras recém-fundadas, a lançar novas revistas em Acesso Aberto, geralmente baseadas no princípio comercialmente atraente de alta taxa de aceitação/alto volume de produção.
No extremo do espectro, os chamados “editores predatórios” lançaram plataformas “sem frescuras” que acrescentam pouco valor à literatura, mas extraem vastos recursos do financiamento da investigação.
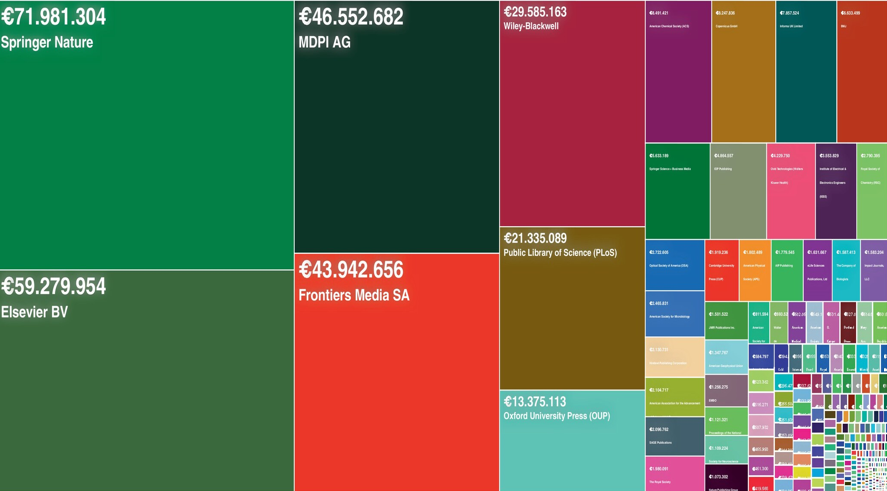
No ranking de receita bruta da receita da APC, Springer-Nature (18%) e Elsevier (15,5%), as duas gigantes da publicação comercial por assinatura, aparecem à frente de MDPI (11%), Frontiers (10,5%), Wiley ( 8%) e PLOS (5,5%) (Figura 3 a seguir, https://openapc.net ; OpenAPC, 2023 ; Pieper & Broschinski, 2018 ).
Acordos Transformativos são a solução?
Para manter os modelos de publicação tradicionais e para satisfazer a crescente procura de artigos sobre acesso aberto, os editores comerciais estão a explorar “acordos transformativos” com grupos de universidades e instituições de investigação.
O acordo transformativo (Transformative Agreement) visa à transição de um contrato de assinatura/híbrido para o Acesso Aberto AA completo, num pacote de assinaturas de revistas e subsídio para vagas de publicação em AA para revistas que os editores oferecem (resumido na página web da ESAC, https://esac-initiative .org/about/transformative-agreements/ ).
Em 2022, por exemplo, um grupo de universidades japonesas (Tohoku University, Tokyo Institute of Technology, Sokendai, Tokyo University of Science) fez um acordo de AT com Wiley ( https://prtimes.jp/main/html/rd/p/ 000000003.000088592.html ).
Em 2023, a JUSTICE, como um consórcio de 563 bibliotecas universitárias, chegou a um acordo com a Elsevier. Essas medidas são certamente um progresso em direção à implementação de publicações de acesso totalmente aberto.
Não está claro como eles contribuem para limitar o custo cada vez maior das assinaturas de periódicos e dos encargos da APC, uma vez que nenhum detalhe de cada acordo foi divulgado.
No Japão, o acordo de AT com grandes editoras ainda está limitado a alguns grupos universitários, e as instituições de investigação não educativas são excluídas. A transparência e o aumento do tamanho do consórcio a nível nacional são necessários para fazer um acordo melhor.
Na Alemanha, um consórcio de 700 instituições de investigação (DEAL, https://deal-konsortium.de ) negociou um único acordo com cada grande editora que inclui elementos “transitórios” (TA) e AA de forma mais transparente, publicando cada acordo. Um quadro unificado com mais transparência é ideal para acordos futuros.
Como alcançar o Acesso Aberto, então?
A maneira mais direta de obter acesso totalmente aberto aos artigos publicados é pagar a APC aos editores (Gold OA, que significa a publicação aberta imediata do artigo final totalmente editado e tipografado).
No entanto, a APC deve ser coberta por alguém e muitas vezes cabe aos autores, que têm de usar os seus orçamentos de investigação para cobrir os custos.
A UE está a tentar definir um orçamento separado para a APC para proteger o financiamento da investigação. O MEXT e as universidades japonesas também estão tentando garantir fundos para a APC.
Mas estes fundos são geralmente insuficientes para cobrir a APC das revistas de primeira linha e a maioria dos autores ainda deve pagar uma proporção da APC a partir do dinheiro da sua subvenção.
É improvável que as APC definidas por editores comunitários ou sociais sejam competitivas em relação aos editores de acesso aberto recém-fundados, especializados em publicação de alto volume e baixo limiar, alguns dos quais podem ser considerados “predatórios” com práticas de publicação problemáticas.
Uma opção alternativa é permitir a deposição gratuita de uma cópia dos manuscritos em um repositório de dados ou servidor de pré-impressão, conforme implementado em pesquisas financiadas pelo NIH nos EUA (PubMed Central, https://www.ncbi.nlm.nih. gov/pmc/ ).
Nesta opção (Green OA), a versão final dos manuscritos está disponível em formato de assinatura, e versões um pouco anteriores são fornecidas em acesso aberto.
No Japão, estão planeados novos repositórios de dados para distribuir todas as obras financiadas pelo governo com acesso aberto até 2025, conforme prometido no Comunicado da Cimeira do G7 de 2023.
Esta opção não é ideal, uma vez que ter duas versões relacionadas pode confundir os leitores e a execução de repositórios de dados em cada universidade – muitas vezes sem padrões comuns – seria ineficaz em termos de custos e potencialmente sofreria instabilidade a longo prazo.
Talvez repositórios de pré-impressão estabelecidos (arXiv, bioRxiv e outros) cobririam a necessidade da maioria dos manuscritos científicos escritos em inglês. Equilibrar o custo, a acessibilidade e a avaliação da qualidade (branding) no complexo negócio da publicação não é uma tarefa fácil.
É necessário um compromisso para garantir o acesso aberto, respeitando simultaneamente a capacidade dos editores de fornecer serviços eficazes à comunidade.
Cada parte ainda está explorando a melhor solução possível.
Como as tecnologias de IA transformarão a ciência aberta?
ChatGPT e outras ferramentas de IA estão transformando nossa abordagem de coleta de informações, resumo, gerenciamento de dados e redação de manuscritos.
Muitas revistas científicas permitem que os cientistas utilizem ferramentas de IA para a preparação de manuscritos, desde que os autores humanos assumam a responsabilidade pela forma final do manuscrito.
O uso de ferramentas de IA também é benéfico para autores com formação em língua diferente do inglês, nivelando o campo de atuação para a comunicação científica e permitindo uma maior globalização da publicação científica.
O uso da IA não se limita apenas à escrita. Uma plataforma de IA simplificada que permite a consolidação de dados primários até um conjunto completo de figuras, anexado ao texto manuscrito, não é mais uma fantasia.
O lado negro desta tendência é que os periódicos já estão recebendo artigos profundamente falsificados com dados sintéticos.
As ferramentas de integridade de imagem usadas por algumas redações de periódicos para detectar dados falsos também são baseadas em IA. Eles agora podem detectar duplicatas em toda a literatura, e abordagens semelhantes estão em desenvolvimento para dados brutos e estatísticas. No entanto, permanece uma questão em aberto se conseguirão acompanhar os dados sintetizados pela IA generativa avançada.
O uso de IA para revisão de manuscritos confidenciais é frequentemente proibido devido à preocupação com o vazamento de dados para a plataforma de IA e a possíveis preconceitos adicionais introduzidos na revisão por pares baseada em especialistas humanos.
No entanto, já foram implementados serviços para revisão e avaliação simplificada de manuscritos em servidores de preprints. O uso de tais informações para complementar a revisão de manuscritos baseada em especialistas humanos pode ser potencialmente uma boa maneira de equilibrar preconceitos na opinião de um pequeno número de editores e revisores durante a avaliação do manuscrito.
O uso de ferramentas de IA para elaboração de relatórios de revisores também é aceito, desde que detalhes específicos do artigo sejam mascarados. Os periódicos estão considerando a implementação de assistentes de IA para revisores, a fim de garantir a imparcialidade e remover agressões desnecessárias nos relatórios.
O futuro da Ciência Aberta
O objetivo do movimento de ciência aberta não é apenas partilhar artigos com o público, mas também partilhar os materiais e dados brutos utilizados para produzir artigos. O compartilhamento de dados, protocolos e reagentes ajudaria outros a reproduzir e ampliar o trabalho e a verificar a credibilidade dos trabalhos e autores.
O estilo tradicional de artigos impressos ou PDF pode entregar apenas uma fração das informações dos trabalhos selecionados pelos autores. A IA ajudar-nos-ia a descobrir valores ocultos, vistos de diferentes perspectivas, em dados brutos que os autores possam ter perdido. Os principais periódicos obrigaram os autores a compartilhar dados brutos e protocolos.
O arquivamento digital de todos os dados e atividades do laboratório seria o próximo desafio. Talvez uma futura IA crie um primeiro rascunho com um clique a partir do banco de dados do laboratório. Tal função poderia ser incluída na base de dados preparada pelos grandes editores.
No entanto, isso causaria o problema da quebra de confidencialidade. A maioria dos laboratórios ainda usa cadernos escritos e os cientistas podem não querer vigilância excessiva no laboratório. Deve ser considerada a implementação da base de dados laboratorial e institucional.
Observação final
A situação atual da publicação de pesquisas é um campo de batalha para cientistas, editores e agências de financiamento em busca da melhor solução para publicar artigos com custos de publicação ideais, mantendo alta a qualidade e a credibilidade das publicações, com pouca ou nenhuma restrição ao acesso aos artigos e dados associados.
Nenhuma solução fácil está disponível neste momento, especialmente para cientistas e instituições com montantes limitados de apoio financeiro. É provável que as tecnologias de IA em rápida evolução mudem drasticamente este cenário.
Por exemplo, a assistência da IA para o tratamento de manuscritos pode reduzir a carga dos editores de revistas, acelerando o processo de triagem, verificação de qualidade e revisão dos manuscritos submetidos, e reduzindo o custo do tratamento e publicação dos manuscritos.
A pesquisa bibliográfica mediada por IA melhoraria a eficiência de encontrar artigos adequados para citar e ajudaria os cientistas a permanecerem atualizados sobre os progressos mais recentes.
Tais funções também podem substituir, pelo menos em parte, a função de selecionar e classificar artigos de alta qualidade e impacto, papel que os periódicos de primeira linha têm desempenhado.
== REFERÊNCIA ==
Arita, M., Pulverer, B., Uemura, T., Sakuma, C., & Hayashi, S. (2024). Publishing in the Open Access and Open Science era. Genes to Cells, p, 1–7. Disponível em: https://doi.org/10.1111/gtc.13100 Acesso em: 18 fev. 2024.