Delegações de organizações que realizam pesquisas e financiam pesquisas de 38 nações e seis continentes, incluindo ministérios da educação e pesquisa, financiadores, líderes universitários e de pesquisa, bibliotecas e consórcios de bibliotecas de nível nacional, cientistas e acadêmicos, reuniram-se na 16ª Conferência de Acesso Aberto de Berlim ( B16), realizada de 6 a 7 de junho de 2023 em Berlim.
A declaração que se segue representa o forte consenso de todas as delegações presentes na reunião.
A transição global para o acesso aberto deve avançar a um ritmo muito maior Através das suas negociações de acesso aberto, as comunidades de investigação em todos os continentes estão a tornar os resultados da investigação mais visíveis e acessíveis, sem custos para os leitores ou autores, para o benefício de todos, mas querem avançar mais rapidamente. Os editores devem oferecer acordos de acesso aberto transformadores e transitórios a todos como padrão e trabalhar em ritmo e escala para efetuar uma transição completa, rápida e permanente do acesso pago aos resultados da pesquisa.
A desigualdade é incompatível com a publicação acadêmica O progresso na eliminação dos acessos pagos às subscrições não deve correr o risco de criar barreiras à participação na ciência aberta e na bolsa de estudos. A transição para o acesso aberto deve ser verdadeiramente inclusiva e refletir a pluralidade de disciplinas de investigação, tópicos, línguas e resultados. Preços regionais diferenciados (geopricing) de serviços de publicação de acesso aberto, que refletem as posições culturais, políticas e financeiras de todas as comunidades, são do interesse de toda a comunidade de investigação global e apoiam os objetivos da bolsa de estudos. Os modelos de publicação de acesso aberto baseados em elevados custos de publicação são injustos. Os preços dos serviços de publicação devem ser globalmente justos, transparentes, acessíveis e sustentáveis.
A autogovernança acadêmica é um imperativo na publicação acadêmica A garantia de qualidade no processo de revisão científica por pares deve ser claramente separada dos processos associados à prestação de serviços de publicação, para evitar práticas que rebaixem os padrões, a fim de aumentar as receitas dos editores. A independência editorial deve ser garantida.
A escolha do autor e os direitos do autor devem estar totalmente habilitados Apoiamos fortemente a retenção de direitos autorais e de todos os direitos contidos neles pelos autores. Os acordos de acesso aberto com editores devem estipular que os autores concedam apenas licenças “limitadas” ou “não exclusivas” aos editores, e licenças liberais Creative Commons (CC) (por exemplo, CC-BY) devem ser aplicadas como opção padrão. Mantendo o espírito e os objetivos do acesso aberto, licenças CC mais restritivas (por exemplo, CC-BY-NC, CC-BY-ND e CC-BY-NC-ND) devem funcionar como originalmente pretendido, no que diz respeito aos direitos do autor; consequentemente, os acordos de “licença para publicação” do autor não devem limitar de forma alguma os direitos do autor. A escolha da licença pelo autor não deve afetar o preço dos serviços de publicação.
Os editores podem restaurar a nossa confiança no seu compromisso com a integridade da comunicação académica, trabalhando com todos os membros da comunidade de investigação global para efetuar o acesso aberto completo e imediato, de acordo com os pontos acima indicados.
O objetivo desta postagem no blog é aumentar a conscientização sobre certas questões relacionadas à adoção de identificadores persistentes (PIDs), que impactam especialmente os países em desenvolvimento e propor uma abordagem alternativa que permitirá uma maior inclusão global e uma adoção mais generalizada de PIDs em todo o mundo.
Os Identificadores Persistentes (PIDs) são uma parte importante do ecossistema acadêmico porque fornecem referências duradouras aos recursos digitais. Para conseguir isso, um PID normalmente possui dois componentes: 1. Um identificador exclusivo usado como referência a um recurso e 2. Um serviço que encaminha (resolve) corretamente as referências de recursos ao longo do tempo, mesmo quando sua localização muda. O primeiro fornece uma referência estável de longo prazo para os usuários, enquanto o segundo rastreia a localização atual para que os usuários não precisem fazer isso.
Existem vários tipos diferentes de PIDs disponíveis para recursos acadêmicos. O mais reconhecido para recursos acadêmicos é o DOI (Digital Object Identifier), mas também existem ARKs, PURLs, Handles e URNs, todos disponíveis há pelo menos duas décadas. Os identificadores, tradicionalmente utilizados no mundo dos repositórios, possuem uma infraestrutura robusta que fornece resolução para o sistema DOI. Os ARKs, também comumente encontrados em serviços de bibliotecas, arquivos e museus, possuem uma infraestrutura flexível e descentralizada. (1) Independentemente do tipo, os PIDs promovem citação e descoberta eficientes de recursos acadêmicos.
Então, por que então, se um recurso já possui um Handle ou outro tipo de PID, você ainda precisaria adquirir um DOI? Contanto que o serviço mantenha adequadamente o link do identificador exclusivo para o recurso, realmente importa que tipo de PID você usa?
Ecossistemas de pesquisa gerenciados com base em coleções de metadados baseados em DOI
Embora o objetivo original dos serviços de PIDs fosse oferecer persistência, algumas Agências de Registro de DOI ou “RAs” (2) têm desenvolvido serviços de valor agregado com os metadados que coletam, que são então reaproveitados como parte de uma oferta de serviço de valor agregado. transformando-o em uma espécie de ecossistema de pesquisa gerenciado. Pelo menos duas agregações baseadas em DOI (Crossref e Datacite) foram criadas para fins de descoberta, rastreamento e análise da produção de pesquisa.
Crossref, por exemplo, apresenta a visão de um “ nexo de pesquisa ”:
O nexo de pesquisa vai além da ideia básica de apenas ter identificadores persistentes para conteúdo. Objetos e entidades como artigos de periódicos, capítulos de livros, subvenções, preprints, dados, software, declarações, dissertações, protocolos, afiliações, contribuidores, etc. devem ser todos identificados e isso ainda é uma parte importante do quadro. Mas o mais importante é a forma como se relacionam entre si e o contexto em que constituem todo o ecossistema de investigação. A base do nexo de pesquisa são os metadados; quanto mais ricos e abrangentes forem os metadados nos registos Crossref, maior será o valor para os nossos membros e para outros, incluindo para as gerações futuras.
Organizações dentro da comunidade de pesquisa juntam-se ao DataCite como membros para poder atribuir DOIs a todos os seus resultados de pesquisa. Desta forma, os seus resultados tornam-se detectáveis e os metadados associados são disponibilizados à comunidade. A DataCite então desenvolve serviços adicionais para melhorar a experiência de gerenciamento de DOI, tornando mais fácil para nossos membros conectar e compartilhar seus DOIs com o ecossistema de pesquisa mais amplo e avaliar o uso de seus DOIs dentro desse ecossistema.
Embora os serviços de valor agregado, por si só, sejam bem-vindos, há duas questões que surgem quando as agregações DOI são comercializadas como um único ponto de referência para resultados acadêmicos.
== Barreiras de custo ==
Em primeiro lugar, existem barreiras de custos substanciais à adopção de DOIs para organizações em países em desenvolvimento. Os custos de cunhar DOIs (ou de aderir ao DataCite ou Crossref – mesmo como um consórcio) tornam-nos inacessíveis em muitas partes de África, Ásia e América Latina, onde muitas vezes há poucos ou nenhuns orçamentos para estes tipos de serviços. Além disso, as taxas de câmbio flutuantes em muitos países significam que os custos futuros podem ser altamente imprevisíveis. Embora todos os PIDs exijam alguns recursos para mantê-los – ou corram o risco de se tornarem inativos ou inacessíveis – alguns PIDs, como Handles e ARKs, são muito mais baratos de adquirir.
Existem programas para ajudar países com menos recursos (como o programa Global Equitable Membership em Crossref ou o Global Access Fund da Datacite), no entanto, estes programas proporcionam apenas alívio temporário ou parcial e não abordam as restrições financeiras fundamentais para muitas organizações. O Datacite Global Access Fund, por exemplo, oferecerá o registo de DOIs gratuitamente durante um ano, e depois as organizações deverão fornecer um plano de sustentabilidade descrevendo como planeiam continuar a aceder a estes serviços após o período de financiamento. Esta não é uma solução a longo prazo, mas apenas incentiva as organizações a aderirem, deixando-as confrontadas com a questão dos custos quando o ano terminar. O programa Crossref Global Equitable Membership oferece isenções para organizações em alguns países de baixa renda, mas cobre apenas um subconjunto de países e instituições que enfrentam sérias restrições financeiras.
== Exemplos ==
América Latina: De acordo com uma análise da LA Referencia de mais de 4,5 milhões de registros de metadados colhidos de periódicos e repositórios na América Latina, apenas cerca de 20% possuem DOIs. Segundo LA Referencia, a principal razão para a baixa cobertura do DOI são os custos (em dólares americanos) que estes serviços representam para universidades e instituições de pesquisa. Como alternativa aos DOIs, o Instituto Brasileiro de Informação em Ciência e Tecnologia (IBICT-Brasil) e o LA Referencia (apoiado pelo SCOSS) estão trabalhando no fornecimento de umasolução tecnológica descentralizada baseada em identificadores ARK . Esta iniciativa busca apoiar a atribuição e resolução de identificadores por meio de uma rede de recursos fornecidos por instituições brasileiras, e também está sendo considerada por outros países da América Latina.
África: O mesmo problema existe em África. No projeto AfricaConnect, a WACREN (Rede de Investigação e Educação Ocidental e Central) está a colaborar com o Fórum Regional de Universidades para o Desenvolvimento de Capacidades na Agricultura (RUFORUM), uma rede de 163 universidades africanas em 40 países africanos para fornecer plataformas contemporâneas que permitam a partilha de dados de investigação. e publicação de acesso aberto. A colaboração é importante para o avanço da investigação e da educação na agricultura na região, melhorando as melhores práticas de gestão de dados de investigação, especialmente no que diz respeito aos dados FAIR e às práticas de ciência aberta. Os PIDs são um aspecto importante da iniciativa para garantir a permanência dos recursos. No entanto, com a enorme variedade e volume de resultados de investigação relacionados com o projeto, os DOIs com acesso pago não são uma opção. Se fossem necessários, isto abrandaria a taxa de utilização das IDP, limitaria a sua adopção e dificultaria a colaboração tanto em África como com a comunidade de investigação global. As NRENs africanas, portanto, estão focadas na utilização de ARKs que são de aquisição gratuita e que podem ser fornecidos diretamente às universidades.
== Risco de monopolização ==
Possivelmente mais problemático do que a questão dos custos é o risco de monopolização. Uma exigência global de um DOI (e, portanto, de ser representado na agregação de metadados) por parte de financiadores e governos, para que um recurso seja “contado” ou considerado “legítimo”, tem o potencial de criar um sistema quase monopolista, que dá uma poucos jogadores influenciam indevidamente e introduz o risco de especulação. Particularmente preocupante é a narrativa que associa ter um DOI à “confiabilidade” ou “integridade” geral da investigação. Crossref, por exemplo, postou recentemente um blog sobre isso, dizendo:
Um benefício específico de uma rede de metadados rica e transparente é a oportunidade de inferir julgamentos sobre a integridade do registo académico (ISR). Amanda Bartell, Head of Member Experience, destacou que a comunidade concorda que a disponibilidade de informações sobre as relações entre resultados de pesquisa, instituições e outros elementos do ecossistema acadêmico juntos fornecem um contexto essencial para decidir sobre a confiabilidade das organizações e de seu conteúdo publicado. Por outro lado, pode tornar mais difícil para as partes transmitirem informações como confiáveis quando esse contexto está faltando.
Se esta perspectiva for amplamente adoptada, terá um efeito seriamente prejudicial nos países em desenvolvimento porque muitos dos seus resultados não serão incluídos nessas colecções centralizadas de metadados. Entretanto, as organizações fora do norte global já lutam com uma menor visibilidade e credibilidade percebida da sua investigação. Os requisitos para atribuir DOIs para serem considerados legítimos apenas agravarão ainda mais esta situação. Inferir uma relação entre a qualidade ou integridade de um recurso e ter um DOI é simplesmente errado e deve ser evitado.
== O caminho a seguir ==
A capacidade de descoberta e a persistência são fundamentais para garantir que os resultados da investigação sejam amplamente utilizados e tenham o impacto mais amplo. No entanto, isto pode e deve ser facilitado de uma forma que seja flexível às necessidades de todos na comunidade académica e, tanto quanto possível, reduza as desigualdades estruturais. Em vez de concentrarmos os nossos esforços na centralização e utilização de alguns serviços seletivos de DOI – o que acabará por excluir muitos devido a barreiras financeiras – o melhor caminho a seguir é que as instituições, países e regiões escolham o serviço PID mais adequado em seu próprio contexto e condições locais. Somente desta forma poderemos garantir a adoção mais ampla possível de PIDs em todo o cenário acadêmico. E, embora exista uma proposta de valor para focar em apenas um ou dois serviços PID globais,
Além disso, a utilização de vários tipos de PID não resulta necessariamente em silos de metadados. A harmonização dos elementos de metadados nos diferentes serviços PID deve ser suficiente para garantir a interoperabilidade das colecções, ao mesmo tempo que cria as condições para um bem comum académico mais inclusivo e duradouro. Conforme articulado no Kit de Ferramentas de Ciência Aberta da UNESCO, Reforçando Infraestruturas de Ciência Aberta para Todos , “a ciência aberta deve basear-se em práticas, serviços, infraestruturas e modelos de financiamento de longo prazo que garantam a participação igualitária de produtores científicos de instituições e países menos privilegiados”.
O COAR há muito defende um ambiente distribuído, mas interoperável, como crítico para um ecossistema resiliente e bibliodiverso, ao mesmo tempo que reduz os riscos de dependência de serviços. Esta abordagem também foi sublinhada na Recomendação da UNESCO sobre Ciência Aberta, que incentiva os membros a adotarem “infraestruturas federadas de tecnologia da informação para a ciência aberta… e infraestruturas, protocolos e padrões robustos, abertos e geridos pela comunidade para apoiar a bibliodiversidade e o envolvimento com a sociedade”( 3). Como tal, instamos a comunidade em geral a considerar as perspectivas aqui apresentadas e a garantir que as soluções globais refletem as necessidades e exigências de todos os países e regiões.
(2) A Fundação DOI é financiada por taxas anuais pagas pelas agências de registro (RAs) e outros membros. A Fundação gerencia o sistema DOI em nome das agências que administram os registros DOI. Os registros DOI alocam prefixos DOI, registram nomes DOI e fornecem um esquema de metadados associado a cada registro DOI. Existem atualmente 12 agências de registro, a maioria delas focada em cunhar DOIs para recursos acadêmicos.
(3) Da Recomendação da UNESCO sobre Ciência Aberta. 2022. (iii) Investir em infraestruturas e serviços de ciência aberta. Seção 18e.
Es la disponibilidad gratuita en la red, permitiendo a cualquier usuario la lectura, la descarga, la copia, la distribución, la impresión, la búsqueda o el uso para cualquier propósito legal, sin ningún tipo de barrera económica, legal o técnica.BOAI, 2022
Ciencia abierta
Es un constructo inclusivo que combina diversos movimientos y prácticas con el fin de que los conocimientos científicos estén abiertamente disponibles y sean accesibles para todos, así como reutilizables por todos… Unesco, 2021
Nos últimos anos, reprodutibilidade e transparência têm sido temas importantes na publicação científica. Embora muitos periódicos, agências de financiamento e instituições tenham introduzido políticas de dados de pesquisa para combater a crise de reprodutibilidade , há uma necessidade de implementar melhor os princípios FAIR , que visam tornar os dados localizáveis, acessíveis, interoperáveis e reutilizáveis, a fim de maximizar seu uso.
Esta é uma tradução simples de Elisabeth Dudziak da matéria publicada no Blog The Publication Plan intitulada Will standardised research data policies make publishing more FAIR?
Por exemplo, o editor da Molecular Brain , Tsuyoshi Miyakawa, relatou que, desde 2017, ele solicitou dados brutos para 41 artigos antes da aceitação, dos quais 97% retiraram ou foram rejeitados devido a dados brutos insuficientes.
Como resultado, a política de dados de pesquisa da revista, que estabelecia que dados brutos relevantes para estudos deveriam estar disponíveis mediante solicitação, foi atualizada para exigir o depósito dos dados nos quais as conclusões do manuscrito se baseiam.
Embora a adoção de políticas de dados esteja aumentando, a variação entre as políticas pode tornar a conformidade um desafio.
Depois de revisar as políticas de vários editores e construir consenso com as partes interessadas por meio do Grupo de Interesse de Implementação e Padronização de Políticas de Dados RDA , eles definiram 14 recursos de políticas de dados de pesquisa de periódicos organizados em seis tipos / camadas de políticas padrão. Os tópicos incluem:
Citação de dados
Repositórios de dados
Declarações de disponibilidade de dados
Padrões e formatos de dados
Revisão por pares de dados de pesquisa
Tanto Miyakawa quanto os autores da estrutura enfatizam a necessidade de colaboração em toda a comunidade de pesquisa mais ampla para apoiar e conduzir a implementação e adoção de políticas de dados de pesquisa. Barend Mons, co-líder da iniciativa GO FAIR , compartilha essa opinião em um artigo da Nature World View e chega a dizer que 5% dos fundos de pesquisa devem ser usados para garantir que todos os dados de pesquisa sejam reutilizáveis por humanos e máquinas, com financiamento retido, a menos que políticas de dados de pesquisa estejam em vigor.
Embora essa sugestão possa não ser popular entre financiadores e acadêmicos, ele afirma que há um excelente retorno sobre o investimento devido ao tempo e dinheiro atualmente perdidos na ‘disputa de dados’.
Como observa Mons, a chave é construir capacidade, permitir a colaboração e compartilhar boas práticas para que a boa administração de dados se torne a regra, não a exceção.
Dando continuidade ao êxito das edições anteriores e mantendo a parceria desde 2010, o evento é organizado pelos Serviço de Documentação e Bibliotecas da Universidade do Minho (USDB), pela Fundação para a Ciência e a Tecnologia (FCT) e pelo Instituto Brasileiro de Informação em Ciência e Tecnologia (IBICT) e, conjuntamente, pela Universidade Federal do Rio Grande do Norte. A 14ª ConfOA decorrerá em Natal, Brasil, de 18 a 21 de setembro.
A ConfOA pretende reunir as comunidades portuguesa, brasileira, bem como dos restantes países lusófonos, que desenvolvem atividades de investigação, desenvolvimento, gestão de serviços e definição de políticas relacionadas com a Ciência Aberta em todas as suas vertentes, nomeadamente o Acesso Aberto à Informação Científica e os Dados de Investigação.
A ConfOA assume-se como o espaço privilegiado para promover a partilha, discussão e divulgação de conhecimentos, práticas e investigação sobre estas temáticas, em todas as suas dimensões e perspectivas.
Advancing the Transition to Open Science: The Role of the UNESCO Recommendation on Open Science [Apresentação] Oradora convidada: Ana Peršić – Programme Specialist at the Section of Science Technology Innovation Policy at the UNESCO
Um modelo de redes colaborativas representado na iniciativa de rede brasileira de repositórios institucionais de dados de pesquisa [Apresentação] Autores: Ana Julia Lopes, Carolina Howard Felicissimo, Caterina Groposo Pavã, Dileine Amaral da Cunha, Leandro Neumann Ciuffo, Lucia Helena Cunha Vidal, Lucieli Francini Barni, Marieta Marks Low, Rafael Port da Rocha, Rene Faustino Gabriel Junior, Samile Andrea de Souza Vanz, Sônia Elisa Caregnato, Tarciso Tadeu Salvador, Wagner Silva Wessfll, Washington Segundo
Plano de Gestão de Dados Acionável por Máquina, da teoria à prática: uma análise das ferramentas ARGOS e FioDMP [Apresentação] Autores: Viviane Veiga, Patricia Henning, João Cardoso, Filipa Pereira, Simone Dib, Erick Penedo
O guia visa à apresentação de informações técnicas da ferramenta livre DSpace e é voltado aos profissionais de informática e o conteúdo serve, inicialmente, de referência. Como já foi dito, para a construção da BD da Anvisa, o software escolhido foi o DSpace, que é uma ferramenta livre que fornece facilidades para o gerenciamento de acervo digital, utilizado para implementação de repositórios ou bibliotecas digitais.
De acordo com os autores, o presente guia publicado em 2022 não tem a pretensão de ser exaustivo, na medida em que se concentra na implantação do DSpace, apresentando os passos para a instalação, configuração e manutenção do sistema. Desse modo, funciona como apoio à disseminação do conhecimento e transferência de tecnologia.
Autores
Lucas Angelo Silveira Mestre em Ciência da Computação pela Universidade de Brasília (UnB), desenvolvedor e assistente de pesquisa no Instituto Brasileiro de Informação em Ciência e Tecnologia (Ibict).
Mirele Carolina Souza Ferreira Costa Doutoranda e Mestre em Ciência da Computação pela Universidade de Brasília (UnB). Bacharela em Ciência da Computação pela Universidade Federal do Mato Grosso (UFMT). Assistente de pesquisa no Instituto Brasileiro de Informação em Ciência e Tecnologia (Ibict).
Milton Shintaku Mestre e doutor em Ciência da Informação pela Universidade de Brasília, coordenador de Tecnologia para Informação do Instituto Brasileiro de Informação em Ciência e Tecnologia (Ibict).
A chave para o sucesso do Public Knowledge Project (PKP) nas últimas duas décadas tem sido seu compromisso em escrever, manter e liberar plataformas de publicação e fluxos de trabalho de software livre e de código aberto (FOSS) – ou seja, Open Journal Systems (OJS), Open Monograph Press (OMP ) e Open Preprint Systems (OPS) – que oferecem suporte à publicação acadêmica de acesso aberto de última geração.
Da mesma forma que a pesquisa de acesso aberto é uma pesquisa licenciada para ser compartilhada, lida, citada e mais livremente, sem restrições ou taxas, a FOSS é licenciada para ser compartilhada, instalada e modificada livremente. Mais especificamente, a PKP emprega a Licença Pública Geral V3 para seu FOSS e recomenda que aqueles que usam o software apliquem uma licença CC BY 4.0 para suas publicações de acesso aberto.
A congruência de espírito e licença que o PKP alcançou entre o FOSS e o acesso aberto funcionou bem para ajudar a comunidade acadêmica a se encarregar da publicação acadêmica na era digital. O software resultante levou editores, bibliotecários e acadêmicos a publicar milhões de artigos e livros revisados por pares em todo o mundo. Também deu origem a uma nova geração de servidores de pré-impressão FOSS.
Construir plataformas FOSS leva a um modelo distribuído de instalações locais que podem desenvolver capacidades técnicas regionais em escala global. Ele incentiva as contribuições de código entre os usuários, especialmente na forma de plug-ins FOSS para as plataformas. Também facilita o compartilhamento de traduções do software pelos usuários. Os sistemas PKP operam em mais de 30 idiomas, enquanto publicam pesquisas em 60 idiomas. Desta forma, FOSS reflete um espírito de cooperação e colaboração que fundamenta a disseminação de uma ciência mais aberta.
Código aberto + acesso aberto também está dando origem a formas mais equitativas de publicação acadêmica. O melhor exemplo disso é o fenômeno do periódico OA Diamond , no qual nem os autores nem os leitores são cobrados pelo acesso aberto ao conteúdo do periódico. Em 2021, o OA Diamond Journals Study liderado por Arianna Bercerril descobriu que 60% desses diamantes de publicação estão usando OJS, enquanto estimam que pode haver até 29.000 periódicos de diamantes OA. Na verdade, isso pode ser uma contagem insuficiente, visto que em 2021 mais de 30.000 periódicos estavam usando o OJS , quase inteiramente com base nos princípios do diamante (consulte Recursos de pesquisa ).
Em suma, código aberto + acesso aberto permite que o PKP traga uma abertura refrescante e em expansão para a infraestrutura de comunicação acadêmica em escala global.
Há uma década, a comunidade científica reconheceu que, para passar do acesso aberto à ciência aberta, era necessário o acesso gratuito e irrestrito ao conhecimento científico. Isso significava valorizar, compartilhar e preservar dados, software e outros artefatos digitais da pesquisa, mas o caminho para participar tinha que ser mais rápido e simples para que a prática ganhasse força. Esta é uma tradução livre da matéria publicada no website SPARC.
A União Europeia decidiu financiar o CERN (Organização Europeia para Pesquisa Nuclear) por meio do projeto OpenAIRE para construir um repositório abrangente para garantir que todos os pesquisadores tenham um local para carregar facilmente software, dados, pré-impressões e outras saídas digitais.
Esse foi o começo doZenodohttps://zenodo.org , que o CERN e o OpenAIRE lançaram em 2013. Desde então, a plataforma global gratuita se expandiu mais rápido do que se imaginava. Ele agora tem 25 milhões de visitas por ano, hospeda mais de 3 milhões de uploads e mais de 1 petabyte de dados. Este ano marca o 10º aniversário da plataforma e hoje o Zenodo é amplamente visto como um local confiável para preservar materiais de pesquisa que podem ser úteis para outras pessoas no avanço da ciência.
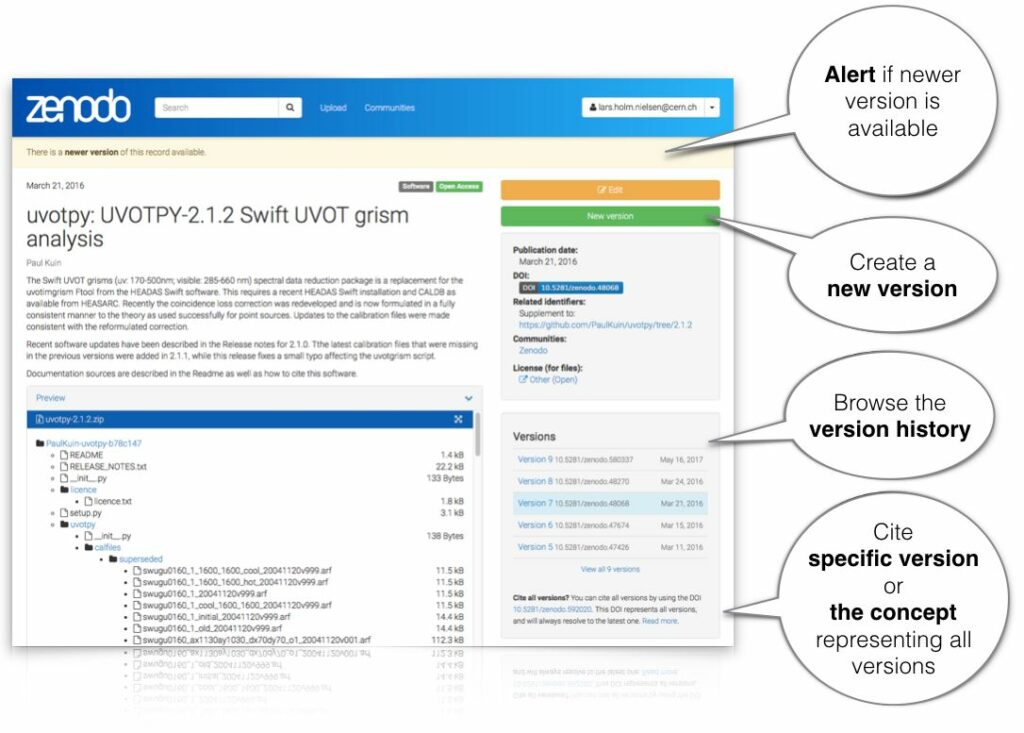
Desde 2017, o Zenodo permite que os usuários atualizem os arquivos do registro depois que eles se tornam públicos e os pesquisadores podem citar facilmente versões específicas de um registro ou citar, por meio de um DOI de nível superior, todas as versões de um registro. O suporte de versão DOI foi um dos recursos mais solicitados para o Zenodo e foi desenvolvido em conjunto pela equipe Zenodo da OpenAIRE e pela equipe B2SHARE da EUDAT como um módulo de extensão para a plataforma de repositório digital Invenio do CERN, que alimenta o Zenodo e o B2SHARE. Leia mais sobre o funcionamento interno do recurso no DOI Versioning FAQ .
No CERN, Lars Holm Nielsen, engenheiro de software e gerente de projeto, e Tim Smith, executivo de projeto e líder do grupo, foram os responsáveis pela realização do novo repositório. Nielsen havia acabado de deixar um cargo no Observatório Europeu do Sul (ESO), onde trabalhou com Christopher Erdmann, um bibliotecário, ajudando a tornar os dados astronômicos abertos e detectáveis tanto para o público quanto para os cientistas. Eles mantiveram contato depois que ambos deixaram o ESO.
Embora separados por um oceano, os três foram fundamentais para a criação do Zenodo — Nielsen no CERN fez o desenvolvimento técnico, enquanto Smith e Erdmann projetaram soluções para desafios e se concentraram no alcance da comunidade. Tanto a base da OpenAIRE na Europa quanto a base da Erdmann nos Estados Unidos e uma grande rede profissional foram fundamentais para ganhar força para a Zenodo.
Depois de considerar vários nomes mais genéricos (Research Share, por exemplo), o sistema foi nomeado Zenodo, uma homenagem a Zenodotus, o primeiro bibliotecário da Biblioteca Antiga de Alexandria e o primeiro criador registrado de metadados.
O repositório foi promovido como um balcão único que acolheu pesquisas de todo o mundo e de todas as disciplinas. Ele acelera o compartilhamento da ciência, permitindo que os pesquisadores compartilhem artefatos a qualquer momento sem ter que esperar até a publicação dos resultados.
“É uma plataforma criada para capacitar os usuários a realizar tarefas, preservar dados de pesquisa e apoiar a ciência”, disse Nielsen. “Queríamos ter certeza de que não havia desculpa para não compartilhar dados.”
Ao atribuir a cada item um identificador de objeto digital (DOI), o Zenodo fornece um serviço valioso de curadoria de software, dados, artigos, materiais de conferência – tudo o que é necessário para entender o processo acadêmico. Os cientistas são capazes de obter crédito por etapas importantes no processo para o qual contribuíram, em vez do atual ‘todos ou ninguém’ na abordagem de lista de autores de artigos. Os uploads são disponibilizados online imediatamente e o DOI é registrado em segundos.
“Os pesquisadores estavam tendo dificuldade em passar por todas as etapas para obter dados em um repositório”, disse Erdmann, agora morando na Carolina do Norte e diretor associado de ciência aberta da Michael J. Fox Foundation. “Queríamos fornecer uma abordagem mais flexível e remover algumas das barreiras para que as pessoas simplesmente começassem a compartilhar.”
Na última década, Nielsen, Smith e Erdmann continuaram a colaborar no Zenodo, trabalhando em particular com Jose Benito Gonzalez Lopez e Alex Ioannidis em uma pequena equipe que ajudou a expandir o Zenodo em resposta à demanda exponencialmente crescente. O sistema foi desenvolvido sob o programa europeu OpenAIRE e é operado pelo CERN para a comunidade de pesquisa em todo o mundo, contando com a reputação do CERN e experiência em gerenciamento de dados em larga escala, somando-se à credibilidade e estabilidade do Zenodo.
Inicialmente, Zenodo era visto como uma espécie de disruptor.
“Deixar que os pesquisadores façam a curadoria foi um pensamento radical”, disse Smith sobre o conceito. “Esta foi uma mudança no processo, abrindo mão do controle e diminuindo as barreiras para as pessoas se submeterem.”
No entanto, a participação em Zenodo superou as expectativas de muitos – especialmente dos primeiros críticos que o consideraram muito aberto. Com o tempo, conquistou os céticos, como disseram os pesquisadores a outros, e a facilidade de uso atraiu mais para depositar seu trabalho.
“O recurso de ‘comunidades’ no Zenodo permitiu que qualquer pessoa criasse um repositório para seus recursos e ajudou a diminuir as barreiras para que a comunidade maior começasse a compartilhar pesquisas”, disse Erdmann.
Os estudiosos começaram a compartilhar materiais de reuniões e conferências no Zenodo com um link para que tudo pudesse ser descoberto e citado.
Entre os exemplos de estudos impactantes compartilhados no Zenodo:
A plataforma técnica do Zenodo foi de código aberto desde o início, mas nunca foi planejada para ser usada por outros. No entanto, as instituições começaram a usá-lo para construir seus próprios repositórios porque queriam fornecer a experiência do Zenodo a seus próprios pesquisadores.
Isso levou Gonzalez Lopez e Nielsen a obter uma pequena doação do CERN Knowledge Transfer em 2018 para tornar a plataforma facilmente reutilizável. Hoje, a plataforma chamada InvenioRDMhttps://inveniordm.docs.cern.ch é co-desenvolvida por uma colaboração de 25 instituições de pesquisa em todo o mundo – um ganho mútuo para Zenodo e cada uma das instituições.
“É importante que tenhamos uma infraestrutura aberta administrada pela comunidade”, disse Gonzalez Lopez. “Nossa mentalidade era que o repositório fosse usado em todo o mundo por pessoas que não têm recursos e nivelar o campo de jogo.”
Nielsen disse que espera que o Zenodo continue a ser um lugar útil para os pesquisadores compartilharem seus trabalhos e que a plataforma continue muito tempo depois de seu envolvimento.
“Os problemas vêm de ficar maiores”, disse Nielsen. “Minha visão para Zenodo é continuar resolvendo esses problemas enquanto permanecemos inovadores na vanguarda da comunicação acadêmica.”
Sobre o SPARC
SPARC é uma organização de defesa sem fins lucrativos que apoia sistemas de pesquisa e educação que são abertos por padrão e equitativos por design. Acreditamos que todos devem poder acessar e contribuir com o conhecimento que molda nosso mundo.
Como um catalisador para a ação, nossa agenda pragmática se concentra em conduzir mudanças políticas, apoiar a ação dos membros e cultivar comunidades que promovam nossa visão do conhecimento como um bem público. Do nível local ao global, o SPARC trabalha para abordar as maneiras pelas quais nossos sistemas de conhecimento excluem pessoas devido ao racismo, colonialismo e outros legados de injustiça.
A associação do SPARC inclui cerca de 250 bibliotecas e organizações acadêmicas na América do Norte. Essa associação é complementada por coalizões SPARC afiliadas na África , Europa e Japão , bem como organizações membros individuais na Austrália, Hong Kong e Arábia Saudita. Fundada em 1998, a SPARC opera como um projeto independente do New Venture Fund, uma organização sem fins lucrativos 501(c)(3). SPARC é conhecido por sua sigla, que significa Scholarly Publishing and Academic Resources Coalition.
O DOAB – https://www.doabooks.org/ – é um serviço de descoberta dirigido pela comunidade que indexa e fornece acesso a livros acadêmicos de acesso aberto revisados por pares e ajuda os usuários a encontrar editoras confiáveis de livros de acesso aberto. Todos os serviços do DOAB são gratuitos e todos os dados estão disponíveis gratuitamente.
DOAB é um diretório digital de livros de acesso aberto revisados por pares e editores de livros de acesso aberto. O principal objetivo do serviço é aumentar a descoberta de livros OA para que possam atingir um público mais amplo. O DOAB coleta os metadados dos livros, que são usados para maximizar a disseminação, visibilidade e impacto.
Os agregadores podem integrar esses metadados em seus serviços comerciais, enquanto as bibliotecas podem fazer o mesmo em seus catálogos online, tornando mais fácil para acadêmicos e estudantes descobrirem as obras. O diretório está aberto a todos os editores de livros acadêmicos revisados por pares que são publicados em acesso aberto e que atendem aos padrões acadêmicos. Todos os editores incluídos no DOAB são avaliados por seus procedimentos de revisão por pares e políticas de licenciamento.
Identificadores persistentes estão desempenhando um papel fundamental na condução de infraestrutura de pesquisa mais robusta e iniciativas de ciência aberta em toda a América Latina. Este foi o tema principal do evento “Persistent Identifiers (PIDs) and Open Science in Latin America” ( #PIDsLATAM23 ) realizado no dia 18 de abril em Buenos Aires (Argentina) durante csv,conf,v7 .
Organizado por DataCite , ROR e ORCID , o evento contou com a participação de mais de 70 interessados em pesquisa de toda a região da América Latina e de outros lugares, representando 40 instituições diferentes no total.
Destinado a administradores de pesquisa, diretores de bibliotecas e equipe técnica, o programa de dia inteiro apresentou uma série de apresentações detalhadas – todas em espanhol – sobre como os identificadores persistentes estão sendo implementados e usados em contextos nacionais, consorciados e institucionais para promover a abertura ciência e aumentar a capacidade de descoberta e visibilidade da pesquisa na América Latina. O objetivo era apresentar casos de uso e histórias de sucesso e reunir partes interessadas com interesses e desafios compartilhados em um ambiente de língua espanhola.
O primeiro conjunto de apresentações concentrou-se em iniciativas de grande escala que visam permitir a ciência aberta com identificadores persistentes. Gustavo Durand, do The Dataverse Project, discutiu como os PIDs estão sendo implementados na plataforma para disponibilizar dados de pesquisas e outros trabalhos de forma mais aberta; Abel del Carpio, da CONCYTEC no Peru, discutiu a estratégia da organização para alavancar os PIDs em nível nacional; e Washington Segundo do IBICT e LA Referencia discutiram os esforços no Brasil e na América Latina para desenvolver infraestrutura de ciência aberta usando PIDs.
A próxima série de apresentações se concentrou em serviços globais de identificadores persistentes para permitir uma infraestrutura de pesquisa mais aberta e interoperável na América Latina e além, apresentando DataCite (Gabi Mejias), ORCID (Ana Cardoso) e ROR (Maria Gould).
Painelistas da sessão “PIDs como infraestrutura de pesquisa aberta” (da esquerda para a direita) Gabi Mejias (DataCite, Alemanha), Maria Gould (ROR, EUA), Ana Cardoso (ORCID, México).
A terceira e última série de apresentações enfocou implementações específicas de identificadores persistentes na infraestrutura de pesquisa da América Latina. Esta sessão destacou casos de uso institucional na Universidad Nacional de Rosario na Argentina (Paola Carolina Bongiovani, Paulina Freán, Analía Salazar) e Universidad de Chile (Rodrigo Donoso) para implementar identificadores persistentes em sistemas de bibliotecas e repositórios, e exemplos de implementações em nível de consórcio por Consórcios da Colômbia (Paula Saavedra) e eScire (Nydia Lopez e Joel Torres) do México.
Paola Carolina Bongiovani, Paulina Freán, Analía Salazar, “Implementación de PIDs en América Latina REPOSITORIO DE DATOS ACADÉMICOS RDA-UNR dataverse.unr.edu.ar,” https://doi.org/10.5281/zenodo.7860470
Na conclusão do programa, os membros da audiência participaram de uma sessão interativa de brainstorming para compartilhar suas impressões sobre o estado das implementações de PIDs na América Latina e levantar questões e ideias sobre como avançar para alcançar uma maior adoção. Os participantes responderam a três perguntas:
O que você gostaria que acontecesse com os PIDs na América Latina?
Quais são os desafios para a adoção de PIDs na região?
O que podemos fazer para enfrentar esses desafios?
Nas respostas à enquete online, vários temas se destacaram: a importância da infraestrutura compartilhada e da colaboração, a necessidade de tornar a infraestrutura dos PIDs mais acessível, o valor de ter mais treinamento e capacitação e a necessidade contínua de continuar conscientizando de como trabalhar com PIDs e dos benefícios que eles oferecem.
Ao longo do dia, as sessões e o envolvimento dos participantes demonstraram não apenas um alto nível de interesse no tema PIDs e ciência aberta na América Latina, mas também geraram novas ideias e oportunidades para futuras colaborações e ações de acompanhamento.
Nós da DataCite, ORCID e ROR expressamos nossa gratidão pela resposta efusiva a este evento e pelas discussões via satélite que aconteceram nos dias anteriores e seguintes, todas as quais falam do papel de liderança que a América Latina está desempenhando no desenvolvimento de infraestruturas, políticas , e práticas para promover a colaboração em torno do conhecimento aberto, redistribuindo as redes globais de pesquisa e possibilitando que todos os países tenham maior acesso à ciência e à tecnologia. Foi ótimo conhecer pessoalmente a comunidade latino-americana e esperamos continuar trabalhando juntos para construir uma infraestrutura de pesquisa aberta e robusta!
== REFERÊNCIA ==
CARDOSO, Ana; MEJIAS, Gabriela; GOULD, Maria. PIDs and Open Science: Building Community in Latin America. In: “Persistent Identifiers (PIDs) and Open Science in Latin America” (#PIDsLATAM23) held on April 18 in Buenos Aires (Argentina). Disponível em: https://info.orcid.org/pids-and-open-science-building-community-in-latin-america/ Acesso em: 01 jun. 2023.