As gravações da conferência anual da OASPA 2022 Annual Conference: Beyond Open Access (Online – September 20-22 2022) do mês passado já estão disponíveis . Há uma enorme quantidade de conteúdo instigante disponível e esperamos que você ache muito útil.
A conferência anual da Open Access Scholarly Publishing Association OASPA 2022 ocorreu online via Zoom de 20 a 22 de setembro de 2022.
A conferência online de 2022 encorajou os participantes a pensar além do acesso aberto para a academia e práticas científicas equitativas e abordou muitos tópicos oportunos e fundamentais relacionados à comunicação no âmbito da comunicação científica e acadêmica abertas.
A OASPA 2022 foi realizada online para garantir ampla participação e a oportunidade de receber todos para uma reflexão coletiva sobre nossos esforços para garantir que a bolsa de estudos seja aberta e acessível a todos. Quaisquer dúvidas sobre a conferência devem ser encaminhadas para info@oaspa.org . Você pode se inscrever para as atualizações da conferência registrando-se em nossa lista de e-mails e escolhendo ouvir sobre as notícias da conferência.
Conferências anteriores
Informações sobre conferências anteriores da OASPA podem ser encontradas nos seguintes links:
A OASPA é uma comunidade diversificada de organizações engajadas em bolsas abertas com a missão de encorajar e possibilitar o acesso aberto como o modelo predominante de comunicação para produtos acadêmicos. Nossa associação inclui editores de livros e periódicos liderados por acadêmicos e profissionais, em diversas geografias e disciplinas, bem como infraestrutura e outros serviços. Somos um organizador confiável do amplo espectro global de partes interessadas em acesso aberto e um local comprovado para colaboração produtiva. Em nosso trabalho, desenvolvemos e disseminamos soluções que promovem o acesso aberto e garantem uma comunidade de acesso aberto diversificada, vibrante e saudável.
Serviço de Comparação de Periódicos Plan S: aberto para bibliotecas e consórcios de bibliotecas registrarem e acessarem dados de preços e serviços
A cOAlition S lançou ontem, 28 de setembro, o portal do usuário final do Journal Comparison Service (JCS) – https://journalcomparisonservice.org/. Esse serviço on-line seguro e gratuito visa esclarecer as taxas e serviços de publicação e permitir que aqueles que adquirem serviços de publicação entendam melhor como periódicos e editores se comparam em uma série de indicadores-chave.
O Journal Comparison Service (JCS) foi desenvolvido pela cOAlition S para fornecer aos clientes (bibliotecas, consórcios de bibliotecas e financiadores) a capacidade de comparar serviços e taxas de publicação de periódicos e para que os editores respondam às solicitações dos clientes por mais padrões, transparência e preço granular e informações de serviço
A partir de hoje, bibliotecas e consórcios de bibliotecas que negociam e participam de acordos de Acesso Aberto com editoras podem se inscrever no JCS. Depois de assinar o contrato de usuário final , eles podem começar a comparar dados entre periódicos e editores, como frequência de publicação, tempos desde o envio até a aceitação e a faixa de preços de tabela para APCs e preços de assinatura. Fundamentalmente, o JCS também fornece informações sobre como o preço é alocado em um conjunto padrão de serviços, como gerenciamento de revisão por pares, serviços de pós-aceitação (edição de texto, criação de XML etc.) e vendas e marketing.
Desde o lançamento do portal do editor em maio de 2022, vários editores – incluindo a Royal Society, a International Union of Crystallography e a Polish Botanical Society – já responderam positivamente à necessidade de maior transparência da comunidade de pesquisa e começaram a compartilhar informações, em nível de revista, em relação aos serviços que prestam e os preços que cobram de acordo com uma das estruturas de preços e transparência de serviços aprovadas pelo Plano S.
O prazo para o fornecimento de dados de preços e serviços para 2021 é o final de outubro de 2022. Esperamos que até esta data, um número significativo de editores tenha depositado dados neste serviço, respondendo assim aos apelos da comunidade de pesquisa que pediram maior transparência sobre essas questões.
JCS: benefícios para bibliotecas e consórcios de bibliotecas
Ao se registrar no JCS, estabelecimentos de ensino e consórcios de bibliotecas envolvidos na negociação de acordos de Acesso Aberto com editores podem obter informações de preços e serviços mais padronizadas, transparentes e granulares. Essas informações permitem que eles entendam melhor quais serviços e níveis de serviço os editores oferecem e avaliem se as taxas que pagam são compatíveis com os serviços de publicação prestados. Ao mesmo tempo, os editores estão demonstrando seu compromisso com modelos de negócios e culturas de negócios abertos.
Robert Kiley, chefe de estratégia da coAlition S, saudou o lançamento do portal do usuário final, dizendo: . Estamos muito satisfeitos por podermos agora disponibilizar este serviço. Esperamos que seja bem utilizado e se torne o padrão de fato para auxiliar bibliotecas e consórcios de bibliotecas nas negociações de acesso aberto com todas as editoras ”.
Timo Vilén, especialista em informações do consórcio FinELib, comentou: “ Há muito tempo pressionamos por maior transparência em nossas negociações de OA e antecipamos o lançamento deste serviço. Tenho certeza de que nosso consórcio fará bom uso do JCS – e espero que as editoras respondam positivamente ao chamado da comunidade em geral e compartilhem seus dados de preços e serviços ”.
O serviço foi criado e será gerido e gerido pela coAlition S , um consórcio internacional de financiamento de investigação e organizações executoras que implementam o Plano S, um mandato que visa tornar uma realidade o Acesso Aberto total e imediato às publicações de investigação. O cOAlition S é apoiado pela Science Europe e hospedado pela European Science Foundation (ESF).
A Recomendação da UNESCO sobre Ciência Aberta foi adotada pela Conferência Geral da UNESCO em sua 41ª sessão, em 23 de novembro de 2021. A Recomendação afirma a importância da ciência aberta como uma ferramenta vital para melhorar a qualidade e a acessibilidade dos resultados científicos e do processo científico, para preencher as lacunas de ciência, tecnologia e inovação entre e dentro dos países e para cumprir o direito humano de acesso à ciência.
Última atualização: 2 de setembro de 2022
Com a adoção desta Recomendação, os Estados Membros adotaram a cultura e a prática da ciência aberta e concordaram em apresentar relatórios a cada quatro anos sobre seu progresso. Eles também expressaram seu desejo de manter o processo de implementação da Recomendação tão inclusivo, transparente e consultivo quanto o processo que leva ao seu desenvolvimento.
Os Estados Membros são incentivados a priorizar as seguintes áreas na implementação da Recomendação da UNESCO de 2021 sobre Ciência Aberta:
Promover uma compreensão comum da ciência aberta e seus benefícios e desafios associados, bem como os diversos caminhos para a ciência aberta
Desenvolvimento de um ambiente político favorável para a ciência aberta
Investir em infraestrutura e serviços que contribuam para a ciência aberta
Investir em treinamento, educação, alfabetização digital e capacitação, para permitir que pesquisadores e outras partes interessadas participem da ciência aberta
Promover uma cultura de ciência aberta e alinhar incentivos para a ciência aberta
Promover abordagens inovadoras para a ciência aberta em diferentes fases do processo científico
Promover a cooperação internacional e multissetorial no contexto da ciência aberta com vista a reduzir as lacunas digitais, tecnológicas e de conhecimento.
A estratégia de implementação foi elaborada pelo Secretariado da UNESCO para apoiar os Estados Membros na implementação da Recomendação, mobilizando parceiros e atores da ciência aberta dentro e fora da comunidade científica, do nível local ao internacional, para realizar ações para atingir os principais objetivos da Recomendação .
Apresentação da Estratégia de Implementação
A Estratégia de Implementação foi compartilhada com os Estados Membros da UNESCO e a Parceria de Ciência Aberta durante uma reunião de informações on-line sobre a Implementação da Recomendação da UNESCO sobre Ciência Aberta em 28 de abril de 2022.
A administração Biden instrui todas as agências dos EUA a exigirem acesso imediato a pesquisas financiadas pelo governo federal após sua publicação, a partir de 2026.
A nova política recomenda que as agências federais garantam que a pesquisa de seus bolsistas seja disponibilizada em um repositório público sem demora após a publicação.
As agências de pesquisa dos EUA devem tornar os resultados de pesquisas financiadas pelo governo federal livres para leitura assim que forem publicados, anunciou o governo do presidente Joe Biden. Esta é uma mudança importante em relação às políticas atuais que permitem um atraso de até um ano antes que os documentos sejam postados fora dos paywalls.
Como os Estados Unidos são o maior financiador de pesquisa do mundo, a mudança – a ser implementada até o final de 2025, se não antes – é um impulso para o crescente movimento de acesso aberto (OA) para tornar a pesquisa científica publicamente disponível. Isso já foi altamente incentivado pelo Plano S, uma cobrança para OA de embargo zero liderada por financiadores europeus . “É um grande negócio”, diz Peter Suber, que lidera o Projeto de Acesso Aberto de Harvard na Universidade de Harvard em Cambridge, Massachusetts. “Esta nova política dos EUA é um divisor de águas para a publicação acadêmica”, acrescenta Johan Rooryck, diretor executivo do grupo de financiadores da coligação S que está por trás do plano liderado pela Europa.
A mudança de política foi anunciada em 25 de agosto, em orientação que o Escritório de Política Científica e Tecnológica da Casa Branca (OSTP) emitiu para agências federais . O OSTP recomenda que as agências garantam que o trabalho revisado por pares de seus bolsistas seja disponibilizado em um repositório público aprovado pela agência sem demora após a publicação. Cada agência pode desenvolver seus próprios protocolos sobre exatamente como isso deve ser feito – um processo a ser concluído nos próximos seis meses a um ano.
“O povo americano financia dezenas de bilhões de dólares em pesquisas de ponta anualmente”, disse Alondra Nelson, chefe interina do OSTP, em comunicado . “Não deve haver atraso ou barreira entre o público americano e os retornos de seus investimentos em pesquisa.”
A Casa Branca não está insistindo que os artigos também sejam abertos em revistas científicas. Mas com futuros trabalhos de pesquisa nos EUA ficando disponíveis imediatamente em repositórios, os editores podem temer que as bibliotecas cancelem as assinaturas de periódicos. Eles poderiam reagir mudando mais para a publicação OA, dizem os observadores. Até agora, os editores de periódicos responderam principalmente dizendo que estão comprometidos em fornecer opções de acesso aberto aos pesquisadores. No entanto, alguns disseram que esperam que as agências dos EUA também forneçam mais financiamento para a publicação de OA, e outros que estão preocupados com a sustentabilidade de seus negócios.
Acesso sem atraso
A orientação do OSTP baseia-se nas políticas de acesso público dos EUA que datam de quase duas décadas. Em 2008, os Institutos Nacionais de Saúde dos EUA (NIH), um dos principais financiadores da pesquisa biomédica, disse aos cientistas que recebiam suas doações para depositar seus estudos em um repositório público dentro de um ano da publicação. Sete anos depois, o governo do então presidente dos EUA, Barack Obama, estendeu essa exigência para incluir os destinatários de fundos de cerca de 20 outras agências federais. Sob essa política, mais de oito milhões de publicações acadêmicas tornaram-se gratuitas para leitura e, juntas, são visualizadas por três milhões de pessoas por dia.
A última orientação da Casa Branca elimina o período de carência de um ano. Foi desenvolvido no ano passado com a contribuição de várias agências federais, segundo a Casa Branca, que diz que a política reforçará a inovação e a transparência, garantindo que todos tenham acesso aos resultados da pesquisa financiada pelos contribuintes. Trazer a bordo todo o governo federal dos EUA tem sido difícil devido ao grande número de agências e à variedade de pesquisas que elas financiam, da ciência básica e aplicada às humanidades. “Agora teremos acesso aberto de parede a parede”, diz Suber.
Aqueles que acompanham as tendências de acesso aberto estão esperando para ver como a política dos EUA mudará a indústria de publicação científica em geral. “Muito vai depender de como os editores reagem”, diz Robert Kiley, chefe de estratégia da Coalition S.
Em teoria, o foco em repositórios públicos que podem abrigar as versões de artigos aceitos e revisados por pares permite que os periódicos continuem cobrando taxas de assinatura das instituições e mantendo os artigos finais atrás de um paywall. Na prática, eliminar o atraso de 12 meses antes que a pesquisa nos EUA seja aberta pode mudar isso, se os editores temerem perder a receita de assinaturas. “Isso ajudará a acelerar o impulso para mudar o sistema para onde os periódicos são de acesso totalmente aberto”, diz Lisa Hinchliffe, bibliotecária da Universidade de Illinois em Urbana-Champaign.
Também não está claro se as agências de financiamento ou bibliotecas dos EUA ofereceriam aumentar sua ajuda para pesquisadores que precisam cobrir as taxas iniciais por artigo que a maioria dos periódicos solicita para publicação de acesso aberto. Uma análise separadado OSTP sobre a economia da política de acesso público dos EUA , também divulgada em 25 de agosto, observa que o NIH e a National Science Foundation (NSF) atualmente cobrem esses custos. O OSTP estima que essas taxas de publicação atualmente representam cerca de 0,5% do orçamento de pesquisa do NIH. Mas as bibliotecas de pesquisa gastam muito mais: seus gastos com acesso público variam de 0,2% a 11% de seus orçamentos.
Kiley espera que surja um ecossistema de modelos de negócios mistos: alguns periódicos, por exemplo, adotarão modelos que evitam cobrar dos autores taxas por artigo, como contratos em massa com bibliotecas.
Reações do editor
Editores de periódicos contatados pela Naturedizem que apoiam os objetivos da Casa Branca e estão prontos para garantir que os autores possam cumprir os novos requisitos. Um porta-voz da Elsevier, a maior editora científica do mundo, diz que “apóia ativamente o acesso aberto à pesquisa” e espera trabalhar com o OSTP para entender sua orientação. “Acreditamos que é muito cedo para dizer se essa orientação afetará nossos periódicos”, disse Sudip Parikh, executivo-chefe da Associação Americana para o Avanço da Ciência (AAAS) em Washington DC, em um comunicado. A AAAS já permite que os autores publiquem manuscritos aceitos em repositórios institucionais imediatamente após a publicação, e Parikh disse que sua organização está explorando outras maneiras de permitir o acesso a tais manuscritos, o que ajudará a “garantir acesso equitativo à publicação científica para leitores e autores”.
Carrie Webster, vice-presidente de OA da Springer Nature, que publica a Nature , observa que a empresa tem 580 periódicos totalmente OA e 2.000 publicações que estão comprometidas em se tornar totalmente OA. Mas ela acrescenta que a empresa espera ver “um compromisso das agências financiadas pelo governo federal dos EUA para apoiar o ouro OA”, referindo-se ao apoio financeiro para a publicação de artigos OA em periódicos. ( A equipe de notícias da Nature é editorialmente independente de sua editora.)
A Associação de Editores Americanos (AAP) em Washington DC emitiu um comunicado dizendo que o anúncio da OSTP “vem sem consulta formal e significativa ou contribuição pública durante este governo sobre uma decisão que terá ramificações abrangentes, incluindo sério impacto econômico”. Ele disse que tinha preocupações com “sustentabilidade e qualidade dos negócios”. A AAP estava entre as editoras que se opuseram fortemente a uma suposta mudança da Casa Branca na política de acesso público dos EUA em 2019 .
O avanço da ciência aberta em todo o complexo e descentralizado ecossistema de pesquisa continua sendo um desafio para ser totalmente implementado por vários motivos. Iniciativas específicas de ciência aberta, incluindo mudanças nas políticas de periódicos, pré-registro e relatórios registrados representam oportunidades existentes para editores, sociedades, instituições, financiadores e pesquisadores contribuirem para uma mudança cultural mais coordenada nas comunidades de pesquisa.
Em um post 1 de novembro de 2021 no The Scholarly Kitchen , Roger Schonfeld sugeriu que o modelo atual de comunicação científica acadêmica pode ser inadequado para melhorar e sustentar a confiança do público e a confiança na ciência à medida que avança em direção a uma maior abertura e transparência. A crescente politização da ciência, 2-4juntamente com os desafios relacionados na gestão eficaz da comunicação pública da ciência, intensifica a necessidade de construir e sustentar a confiança no processo científico. Depois de delinear as prioridades propostas para a comunidade de comunicação acadêmica contribuir para a construção de confiança na ciência, Schonfeld finalmente aponta para a necessidade de maior coordenação e colaboração entre as partes interessadas no sistema de conhecimento global – editores, pesquisadores seniores, formuladores de políticas, instituições, financiadores, e bibliotecas—para sustentar um ambiente de informação confiável.
A coordenação e colaboração em nível de sistema é um tema convergente em todo o movimento de reforma da ciência aberta. 5–7 A recente adoção8 da Recomendação de Ciência Aberta9 da UNESCO por todos os 193 estados membros oferece um novo sinal de intencionalidade e uma estrutura normativa para a coordenação do sistema global. A pandemia do COVID-19 estimulou a coordenação e a implementação de iniciativas abertas entre várias partes interessadas em todo o sistema de comunicação acadêmica que se alinharam para impedir uma crise global. Especificamente, a declaração emitida em janeiro de 2020 pelo Wellcome Trust sobre “Compartilhamento de dados de pesquisa e descobertas relevantes para o novo surto de coronavírus (COVID-19) ” 10foi assinado por 160 organizações em todo o mundo, incluindo financiadores de pesquisa, editores, provedores de infraestrutura e instituições de pesquisa. Em abril de 2020, um grupo de editores e organizações relacionadas lançou a COVID-19 Rapid Review Initiative 11 para maximizar a eficiência e a velocidade da revisão por pares da pesquisa COVID-19.
Em junho de 2021, o Research on Research Institute12 publicou um relatório13 de seu estudo avaliando se essas iniciativas coordenadas, de fato, mudaram o sistema de comunicação acadêmica, acelerando o acesso aberto, pré-impressão e revisão por pares relacionada de pre-prints, compartilhamento de dados e tempos de publicação da pesquisa COVID-19. Eles descobriram que a pesquisa relacionada ao COVID se tornou mais aberta e acessível gratuitamente, e que a pré-impressão aumentou. No entanto, eles também descobriram que pouco havia mudado na maneira de compartilhar dados relacionados à pesquisa do COVID-19 e, além disso, que os esforços para revisar os pre-prints permaneceram baixos em proporção à produção da pesquisa. 13Os contribuidores reforçaram a coordenação e colaboração do sistema ao recomendar explicitamente que “todos os interessados no sistema de pesquisa devem reconhecer que melhorar a comunicação acadêmica é uma responsabilidade conjunta que requer colaboração e ação coordenada entre os interessados, incluindo o desenvolvimento de políticas com acompanhamento de mecanismos de monitoramento e prestação de contas”. 13, p75
No entanto, a coordenação do sistema para o avanço da ciência aberta, mesmo para a disseminação e verificação do registro científico, e muito menos para todo o ciclo de vida da pesquisa, continua sendo um desafio para ser totalmente promulgada por várias razões. O ecossistema de pesquisa é descentralizado com normas comunitárias socialmente construídas, de modo que a adoção generalizada de mudança de comportamento é complicada. Além disso, instituições, sociedades acadêmicas, editoras e os próprios pesquisadores geralmente têm recursos limitados e objetivos centrais que devem cumprir para sustentar seu trabalho, tornando a propriedade e o envolvimento mais amplos na prática da ciência pouco atraentes ou aparentemente insustentáveis. As estruturas de incentivo institucionalizadas estão desalinhadas com os valores de abertura e transparência, recompensando pesquisadores por serem publicados, compartilhando novos resultados e, finalmente,14,15 E os sistemas geralmente preferem a homeostase, especialmente quando as estruturas de incentivo não são projetadas para promover mudanças.
Portanto, quando os proponentes da reforma da ciência aberta exigem coordenação e colaboração do sistema, pode ser assustador para líderes individuais ou grupos de interessados – editores, sociedades, financiadores, instituições e outros – saber por onde começar, como contribuir e como fazer a diferença, especialmente como um ator em um sistema complexo e dinâmico. Por esse motivo, nosso objetivo é demonstrar como iniciativas específicas de ciência aberta podem fazer parte de um esforço para uma mudança de cultura mais sistêmica nas comunidades de pesquisa e nas partes interessadas.
Teoria da Mudança de Cultura de Pesquisa: Uma Abordagem em Nível de Sistemas
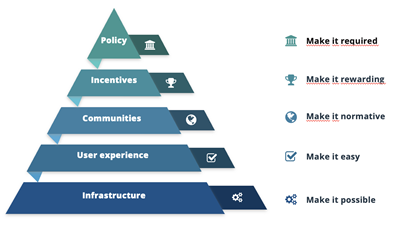
No Center for Open Science16 (COS), desenvolvemos uma teoria demudança de cultura de pesquisa 17 a serviço da ciência aberta, transparente e reprodutível 18 que emprega 5 níveis de intervenção representados pela pirâmide na Figura. Esses níveis são progressivos, refletindo o fato de que a implementação bem-sucedida dos níveis mais altos depende da implementação bem-sucedida dos níveis mais baixos.
Figura. Center for Open Science teoria do modelo de mudança.
Para escalar a adoção de comportamentos abertos por pesquisadores, o COS se concentra em 1) fornecer infraestrutura aberta por meio do Open Science Framework 19 (OSF) de código aberto que torna possível realizar os comportamentos; 2) conduzir o desenvolvimento de produtos centrado no usuário para facilitar a execução dos comportamentos; 3) apoiar a organização de base por meio de treinamento e esforços de construção da comunidade para ativar os primeiros adeptos e tornar seu comportamento visível ; 204) oferecer soluções a periódicos e editores, financiadores, sociedades e instituições para estimular seus incentivos para tornar desejável a prática dos comportamentos; e 5) fornecer e promover uma estrutura de políticas para que as partes interessadas tomem os comportamentos necessários. A implementação efetiva de políticas requer infraestrutura efetiva para praticar os comportamentos e a adesão da comunidade para tratar os comportamentos como boas práticas em vez de encargos administrativos. Esses 5 níveis de intervenção são altamente interdependentes, cada um necessário e nenhum suficiente por si só.
Quando a mudança de comportamento requer mudança de cultura, é essencial considerar as características estruturais da cultura e como elas permitem e constrangem os indivíduos a se comportarem de acordo com suas intenções e valores. Intervenções bem-sucedidas, normativas, de incentivo e políticas exigem infraestrutura eficaz que forneça transições fáceis de como elas se comportam hoje. Da mesma forma, decretar essa mudança de comportamento requer incentivos e políticas sensatas que se alinhem com as ferramentas comportamentais disponíveis para os indivíduos. Para uma aceitação generalizada, a mudança de comportamento deve ser visível para a comunidade para estimular a difusão da inovação.
Iniciativas abertas que podem apoiar a mudança do sistema
É relativamente fácil afirmar que os sistemas precisam mudar para reformar a prática científica. No entanto, essas visões exigem etapas específicas e acionáveis que podem ser apoiadas e implementadas. O COS aponta para essas ações específicas que pesquisadores individuais ou formuladores de políticas em periódicos, editores, sociedades e organizações de financiamento podem tomar para começar a tornar essa visão idealizada uma realidade. Essas etapas derivam do objetivo de garantir que as evidências da pesquisa empírica possam ser reproduzidas (verificadas por meio da verificação dos dados coletados e dos resultados relatados) e replicadas (verificadas por meio da realização dos métodos relatados uma segunda vez). 18 As práticas em que nos concentramos para atingir esses objetivos estão descritas nas Diretrizes de Promoção de Transparência e Abertura (TOP)21,22e incluem transparência de dados subjacentes, materiais de pesquisa, código analítico e desenho do estudo; citação de dados de pesquisa utilizados em estudos; pré-registo de planos de estudos, por vezes com um plano de análise específico; e utilização de políticas ou fluxos de trabalho que incentivem estudos de replicação, nomeadamente Relatórios Registados.
Nossa filosofia vem da otimização de 2 necessidades: 1) atender aos stakeholders onde eles estão, não buscando a perfeição em detrimento de qualquer melhoria, e 2) criar critérios de sucesso claros para resultados ideais. Essa otimização é refletida nos níveis fornecidos pelas TOP Guidelines em que o primeiro nível exige que os resultados da pesquisa divulguem se ocorreu ou não alguma prática aberta (por exemplo, compartilhamento de dados, compartilhamento de código ou pré-registro), o segundo exige transparência para o padrão , e o terceiro verifica se a prática ocorreu em alto padrão (por exemplo, por meio de reprodução computacional).
Uma vez que uma determinada política abrange uma prática de ciência aberta mencionada por um editor, financiador ou periódico individual, um conjunto de ferramentas está disponível para viabilizar a prática. Abaixo estão exemplos dessas ferramentas que usamos para promover a adoção de compartilhamento de dados, pré-registro e um formato de publicação conhecido como Relatórios Registrados.
Os materiais gerados durante o curso de um projeto são muitas vezes perdidos quando a curadoria é deixada como uma reflexão tardia no final de um estudo. Protocolos, conjuntos de dados, instrumentos de pesquisa e código analítico acabam em unidades individuais que podem desaparecer no curso normal da rotatividade em um laboratório de pesquisa. O uso de um espaço de gerenciamento de projetos online que também permite o compartilhamento persistente (quando o projeto está pronto para ser tornado público) reduz os custos para o laboratório focado em obter resultados na literatura publicada. O OSF permite o gerenciamento de projetos e está conectado a registros integrados, repositórios de dados e servidores de pré-impressão. Além disso, ele se conecta a plataformas de controle de versão, como o GitHub, e grandes provedores de armazenamento de dados online, como o Dropbox, para permitir a curadoria. Também oferece preservação de longo prazo em parceria com Internet Archives. 23
O pré-registro é um processo pelo qual um pesquisador afirma que um estudo está prestes a ocorrer e inclui as principais questões de pesquisa e os processos pelos quais o estudo será conduzido. Ao submeter tais declarações a um registro público (talvez após um período de embargo), pesquisável, os consumidores de conhecimento científico podem entender melhor quanta pesquisa é realizada em um campo e podem abrir a proverbial “gaveta” de documentos conduzidos, mas não necessariamente publicados, pesquisar. 24 Quando o pré-registro também inclui um plano de análise específico, ele pode abordar algumas práticas ruins de pesquisa, como relatórios seletivos ou seleção seletiva de uma disseminação não representativa dos resultados da pesquisa. 25
O pré-registro, juntamente com registros de estudos fáceis de usar, permite melhores práticas de pesquisa. O Registered Reports26 (RR) é um formato de publicação que incentiva esse processo. Quando um periódico oferece RRs, ele se compromete a revisar os estudos propostos (ou seja, o pré-registro) para possível publicação. 27,28 Se um periódico revisa e aceita provisoriamente o estudo proposto, compromete-se a publicar os resultados finais independentemente dos principais resultados do estudo . Evidências preliminares constatam que os RRs estão funcionando como pretendido, reduzindo o viés de publicação, 29 aumentando o rigor dos achados relatados, 30 e ainda sendo citados com a mesma frequência que os artigos de formato padrão.
Mais de 300 periódicos oferecem RRs como oferta de publicação, mas vários financiadores também se envolvem com o formato financiando pesquisas que foram aceitas em princípio para publicação. 31 Isso facilita a aplicação de relatórios de resultados porque está vinculado diretamente a uma publicação e há um forte incentivo existente para publicar na comunidade de pesquisa. É importante ressaltar que essa coordenação entre periódicos e financiadores cria um sistema mais amplo que está promovendo a mudança cultural na comunidade de pesquisa acadêmica e é central para nossa abordagem de nível sistêmico para forças interdependentes.
Os exemplos acima destacam o simples fato de que novas expectativas em qualquer comunidade só podem se transformar em novas normas se forem recompensadas, verificáveis e utilizadas. Além disso, a natureza descentralizada da ciência requer coordenação entre pesquisadores, instituições, financiadores e editores de conhecimento científico para fazer progressos significativos em direção a objetivos compartilhados.
Lições Aprendidas na Coordenação do Sistema
Coordenar a mudança do sistema é difícil, especialmente quando os incentivos não estão alinhados com o comportamento normativo desejado. Juntamente com variações de terminologia comunitária e disciplinar, entre outros desafios, mudar a cultura de pesquisa às vezes pode parecer intransponível. Navegar por essas complexidades requer uma abordagem ágil e experimental. Os estudos piloto permitem a exploração de ideias antes da implementação, a pesquisa metaciência (ou ciência da ciência) fornece um mecanismo para estudar as consequências intencionais e não intencionais da mudança, e a comunicação aberta e o feedback permitem que os sistemas se adaptem cedo para permitir que eventuais abordagens políticas sejam alinhadas com o desejado. práticas. O envolvimento da comunidade é fundamental para permitir que os movimentos de reforma ganhem força, e a coordenação e participação entre os grupos de partes interessadas pode criar um mecanismo para melhoria contínua e aceleração da mudança. Uma consideração importante é considerar constantemente os fluxos de trabalho e a experiência dos usuários para que os comportamentos possam ser implementados de maneira mais fácil e eficiente, em vez de serem percebidos como um aro burocrático a ser superado. Finalmente, treinamento e educação são importantes para sustentar e aumentar a adoção de mudanças. Os sistemas preferem a homeostase e é fácil adotar um comportamento anterior, mesmo quando sabemos que é um comportamento que queremos mudar. Simplesmente dizer aos pesquisadores para implementar práticas de ciência aberta é insuficiente. Uma consideração importante é considerar constantemente os fluxos de trabalho e a experiência dos usuários para que os comportamentos possam ser implementados de maneira mais fácil e eficiente, em vez de serem percebidos como um aro burocrático a ser superado. Finalmente, treinamento e educação são importantes para sustentar e aumentar a adoção de mudanças. Os sistemas preferem a homeostase e é fácil adotar um comportamento anterior, mesmo quando sabemos que é um comportamento que queremos mudar. Simplesmente dizer aos pesquisadores para implementar práticas de ciência aberta é insuficiente. Uma consideração importante é considerar constantemente os fluxos de trabalho e a experiência dos usuários para que os comportamentos possam ser implementados de maneira mais fácil e eficiente, em vez de serem percebidos como um aro burocrático a ser superado. Finalmente, treinamento e educação são importantes para sustentar e aumentar a adoção de mudanças. Os sistemas preferem a homeostase e é fácil adotar um comportamento anterior, mesmo quando sabemos que é um comportamento que queremos mudar. Simplesmente dizer aos pesquisadores para implementar práticas de ciência aberta é insuficiente.
Consideremos os RRs. Como mencionado acima, os RRs continuam a crescer em sua adoção desde que foram implementados. Existem esforços da comunidade para aumentar essa adoção32 e inovações para combinar RRs com financiamento e revisão regulatória. 33,34 Esse sucesso não ocorreu isoladamente por um único stakeholder ou sem adaptação. Por exemplo, os esforços de avaliação inicial destacaram os desafios na implementação dos RRs, como a falta de transparência do protocolo. 35 Esses desafios levaram a oportunidades para melhorar e alinhar o processo, especificamente aproveitando a infraestrutura para permitir que os usuários depositem facilmente seus protocolos, sob embargo, se necessário, para que o protocolo aceito do estágio 1 esteja disponível abertamente aos leitores interessados. 36Para que essa iniciativa de reforma da ciência aberta continuasse a crescer e avançar, as partes interessadas tiveram que adaptá-la. Existem muitas possibilidades futuras para RRs, a maioria das quais requer coordenação contínua entre as partes interessadas.
Tempo para dimensionar e sustentar a mudança
A mudança sustentada da cultura de pesquisa virá quando, juntos, passarmos dos primeiros adeptos das práticas de ciência aberta para vários agentes dentro do sistema que coordenam e apoiam a mudança. Iniciativas específicas de ciência aberta que agora estão ganhando força e maior apoio entre financiadores, editores, sociedades e instituições podem fazer parte do esforço de mudança de cultura mais sistêmica em comunidades de pesquisa e partes interessadas. Mesmo pequenos passos para pilotar essas iniciativas nas comunidades podem reunir os insights necessários para minimizar o atrito no início e maximizar os resultados e a escalabilidade ao longo do tempo. Uma maior coordenação dessas iniciativas entre todas as partes interessadas pode permitir um maior retorno sobre o investimento e minimizar os encargos inerentes à mudança.
Chinn S, Sol Hart P, Soroka S. Politicization and polarization in climate change news content, 1985–2017. Sci Commun. 2020;42:112–129. https://doi.org/10.1177/1075547019900290.
Gauchat G. Politicization of science in the public sphere: a study of public trust in the United States, 1974 to 2010. Am Sociol Rev. 2012;77:167–187. https://doi.org/10.1177/0003122412438225.
National Academies of Sciences, Engineering, and Medicine. Open science by design: realizing a vision for 21st century research. Washington, DC: The National Academies Press; 2018. https://doi.org/10.17226/25116.
Organisation for Economic Co-operation and Development. Making open science a reality. OECD Science, Technology and Industry Policy Papers, No. 25. Paris: OECD Publishing; 2015. https://doi.org/10.1787/5jrs2f963zs1-en.
Robson SG, Baum MA, Beaudry JL, et al. Promoting open science: a holistic approach to changing behaviour. Collabra: Psychol. 2021;7:30137. https://doi.org/10.1525/collabra.30137.
Waltman L, Pinfield S, Rzayeva N, et al. Scholarly communication in times of crisis: the response of the scholarly communication system to the COVID-19 pandemic. Research on Research Institute Report. 2021. https://doi.org/10.6084/m9.figshare.17125394.v1.
Giner-Sorolla R. Science or art? How aesthetic standards grease the way through the publication bottleneck but undermine science. Persp Psychol Sci. 2012;7:562–571. https://doi.org/10.1177/1745691612457576.
Nosek BA, Spies JR, Motyl M. Scientific utopia: II. Restructuring incentives and practices to promote truth over publishability. Persp Psychol Sci. 2012;7:615–631. https://doi.org/10.1177/1745691612459058.
National Academies of Sciences, Engineering, and Medicine. Reproducibility and replicability in science. Washington, DC: The National Academies Press; 2019. https://doi.org/10.17226/25303.
Franco A, Malhotra N, Simonovits G. Publication bias in the social sciences: unlocking the file drawer. Science. 2014;345:1502–1505. https://doi.org/10.1126/science.1255484.
Nosek BA, Lakens D. Registered reports: a method to increase the credibility of published results. Soc Psychol. 2014;45:137–141. https://doi.org/10.1027/1864-9335/a000192.
Chambers CD, Feredoes E, Muthukumaraswamy SD, et al. Instead of “playing the game” it is time to change the rules: registered reports at AIMS Neuroscience and beyond. AIMS Neurosci. 2014;1:4–17. https://doi.org/10.3934/Neuroscience.2014.1.4.
Scheel AM, Schijen MRMJ, Lakens D. An excess of positive results: comparing the standard psychology literature with registered reports. Adv Method Pract Psychol Sci. 2021. https://doi.org/10.1177/25152459211007467.
Soderberg CK, Errington TM, Schiavone SR, et al. Initial evidence of research quality of registered reports compared with the standard publishing model. Nat Hum Behav. 2021;5:990–997. https://doi.org/10.1038/s41562-021-01142-4.
Naudet F, Siebert M, Boussageon R, et al. An open science pathway for drug marketing authorization—registered drug approval. PLoS Med. 2021;18:e1003726. https://doi.org/10.1371/journal.pmed.1003726.
[1] Cuevas Shaw L, Errington TM, Mellor DT. Toward open science: contributing to research culture change. Sci Ed. 2022;45:14-17. https://doi.org/10.36591/SE-D-4501-14
Para comemorar o aniversário, o comitê diretivo do Budapest Open Access Initiative (BOAI) publicou um novo conjunto de recomendações baseado em seus princípios originais, no momento atual, e nas apresentações de colegas de todos os âmbitos acadêmicos e regiões do mundo. Esta é uma tradução livre das recomendações atualizadas[1].
Em setembro de 2021, solicitamos os comentários da comunidade global de acesso aberto sobre 12 sugestões . Após recopilar as respostas recebidas por e-mail, organizamos uma série de reuniões pelo Zoom com grupos de interessados e comunidades regionais. Os comentários serviram de apoio a nossas discussões sobre aas novas recomendações, pelo que agradecemos a contribuição de todos aqueles que participaram.
Seguimos comprometidos com os princípios articulados na declaração original do BOAI de 2002 e na declaração do aniversário de 2012. Porém, a história do acesso aberto seguiu evoluindo, por exemplo, com o crescimento do volume global da literatura em acesso aberto, o aumento de uma nova forma de pesquisa que é de acesso aberto desde seu início, o aumento do número de repositórios de acesso aberto, o aumento do número de novas revistas de acesso aberto, o aumento do número de revistas de acesso aberto e o crescimento do uso e a aceitação dos preprints de acesso aberto. Também se produziu uma proliferação de novas políticas de acesso aberto por parte das agências que financiam a pesquisa e das universidades, novos serviços para a aplicação das políticas de acesso aberto, novos elementos práticos de avaliação da pesquisa, novos elementos de infraestrutura para a pesquisa, novas ferramentas, novos modelos de negociação das revistas, novos métodos de revisão por pares, novas opções de acesso aberto para os autores, novas organizações que advogam em favor do acesso aberto e novas associações e alianças.
Estes 20 anos têm aprofundado a compreensão de certos problemas sistêmicos. É necessário saber mais sobre os indicadores de pesquisa em infraestrutura proprietária, o controle comercial de acesso à pesquisa, as medidas de avaliação baseadas nas métricas das revistas, os rankings de revistas, os modelos de negociação das revistas que excluem os autores por motivos econômicos (iguais às revistas de assinatura que excluem os leitores por razões econômicas), os embargos nos repositórios de acesso aberto, os direitos exclusivos dos editores, a versão da revista correspondente a um artigo, e os persistentes mal entendidos sobre os diferentes métodos para facilitar o acesso aberto.
Cada vez temos mais claro que o acesso não é um fim em si mesmo, mas um meio para alcançar outros fins, sobretudo, é um meio para a equidade, a qualidade, a utilidade e a sustentabilidade da pesquisa. Devemos avaliar o crescimento do acesso aberto em função das vantagens e desvantagens para estes outros fins. Devemos eleger estratégias para o crescimento do acesso aberto que sejam coerentes com estes outros fins e que nos acerquem cada vez mais de sua consecução.
Não pretendemos deliberadamente fazer uma lista exaustiva de recomendações. Nós criamos uma longa lista há 10 anos na data de aniversário do BOAI e hoje poderíamos escrever uma lista ainda maior. Sem dúvida, de acordo com nossa experiência, as listas mais curtas podem ser mais eficazes do que as mais longas. Evitam que as recomendações prioritárias caiam sepultadas em uma avalanche de boas recomendações, mas menos relevantes. Ademais, desde a nossa declaração de aniversário, muitos outros grupos elaboraram excelentes recomendações que apoiamos e que, em conjunto, cobrem muito bem todo o espectro. Entre as listas mais longas, destacamos as recomendações da UNESCO de novembro de 2021sobre a Ciência Aberta, por sua magnitude e sua aprovação por parte de 193 países. Nesse sentido, instamos a todos os Estados membros da UNESCO a aplicar os princípios das novas recomendações.
Para manter reduzida nossa própria lista, só elaboramos quatro recomendações prioritárias (ainda que admitindo que há subitens extensamente desenvolvidos). Também nos temos centrado no acesso aberto aos artigos de pesquisa e seus preprints. Apoiamos firmemente os dados abertos, os metadados abertos, as citações abertas, o código aberto, os protocolos abertos, os livros em acesso aberto, as teses e declarações em acesso aberto, as citações, o material didático aberto, projetos digitais abertos, as licenças abertas, os padrões abertos, a revisão por pares aberta e as ferramentas práticas que conformam a ciência aberta. Também vemos as relações de todos os componentes em um ecossistema mais amplo de pesquisa e educação aberta. Porém, fornecer recomendações em todos os âmbitos alongaria enormemente a lista e poderíamos correr o risco de termos uma avalanche.
Esperamos que utilize a etiqueta #BOAI20 nos debates e redes sociais sobre estas recomendações.
14 de fevereiro de 2022
Resumo
O acesso aberto não é um fim em si mesmo, senão um meio para alcançar outros fins. Sobretudo, é um meio para a equidade, a qualidade, a utilidade e a sustentabilidade da pesquisa. Nossas quatro recomendações prioritárias abordam os problemas sistêmicos que criam obstáculos ao progresso para alcançar estes fins.
Alojar os resultados da pesquisa em uma infraestrutura aberta. Alojar e publicar textos, dados, metadados, código e outros resultados digitais da pesquisa em infraestruturas abertas e controladas pela comunidade. Utilizar uma infraestrutura que minimize o risco de futuras restrições de acesso ou controle por parte de entidades comerciais. Nos casos em que, todavia, a infraestrutura aberta não seja a adequada, de acordo com as necessidades atuais, há que seguir desenvolvendo-a.
Reformar o sistema de avaliação da pesquisa e das recompensas para melhorar os incentivos. Ajustar as práticas de avaliação da pesquisa para a tomada de decisões relativas a financiamentos e decisões de contratação, promoção e permanência na universidade. Eliminar os obstáculos para o acesso aberto e criar novos incentivos positivos para o acesso aberto.
Favorecer os canais de publicação e distribuição inclusivos de modo que nunca exclua os autores por motivos econômicos. Aproveitar ao máximo os repositórios de acesso aberto e as revistas sem APC (acesso aberto “verde” e “diamante”). Apartar-se das revistas que cobram para publicar (APCs).
Quando investimos dinheiro em trabalhos de pesquisa publicados em acesso aberto, reforçamos que oacesso abertoé um meio, não um fim. Devemos favorecer modelos que beneficiam todas as regiões do mundo, que são controladas por instituições acadêmicas e organizações sem fins lucrativos, que não concentrem a nova literatura em acesso aberto em revistas dominantes comercialmente, que evitem o estabelecimento de modelos que entrem em conflito com estes objetivos. Não considerar os acordos de “ler e publicar” (acordos transformativos).
Principais recomendações para os próximos 10 anos
Infraestrutura aberta e sua governança
Recomendamos alojar e publicar textos, dados, metadados, código e outros produtos digitais de pesquisa em uma infraestrutura aberta e controlada pela comunidade acadêmica. Referimo-nos a uma infraestrutura construída a partir de um software livre e de código aberto e controlado que cumpra com padrões abertos, com APIs abertas para facilitar a interoperabilidade, sempre que possível, em plataformas abertas em instituições acadêmicas ou sem fins lucrativos. Aqui nós estamos concentrados em plataformas com estas características essenciais, mas apoiamos a grande lista de características que aparecem nos Princípios da Infraestrutura Acadêmica Aberta .
A pesquisa em acesso aberto corre o risco de ficar restrita quando se aloja em uma infraestrutura fechada, proprietária ou comercial. O proprietário em questão pode deixar o conteúdo aberto e pode ser obrigado por contrato a fazer isso durante algum tempo. Os resultados da pesquisa no acesso aberto estão mais seguros nas instituições lideradas pelo mundo acadêmico e com uma infraestrutura não prevista para futuras aquisições de decisões baseadas em maximizar as ganâncias, e que não corram o risco de cerceamento. A adoção de uma infraestrutura aberta liderada pelo mundo acadêmico forma parte da manutenção da pesquisa e de sua sustentação. Também forma parte do processo para separar a capacidade de geração de conhecimento, a revisão por pares, a medição do impacto e a avaliação da investigação do processo de publicação.
Recomenda-se a adoção de infraestruturas abertas com módulos distribuídos, independentes e interoperáveis em lugares de plataformas centralizadas. A centralização cria monoculturas e está gerando riscos de bloqueio e estancamento, inclusive em ausência de monopólios e inclusive quando se trata de infraestruturas abertas.
Quando as universidades, instituições de pesquisa e agências de financiamento selecionarem ou construírem novas plataformas devem insistir no uso de infraestruturas abertas. Quando os países criam plataformas de investigação lícitas, também se deve insistir em que sejam infraestruturas abertas.
Se for necessário usar os serviços de empresas com fins lucrativos, as instituições de pesquisa deverão optar pelas que utilizarem as infraestruturas de código aberto.
Para um propósito determinado em um momento dado, uma infraestrutura fechada poderia ser melhor que uma alternativa aberta. Apesar de reconhecer isso, recomendamos que as instituições acadêmicas considerem melhorar a infraestrutura existente antes de adotar uma infraestrutura fechada. Se as alternativas foram abertas em caso de deficiência, esta poderia ser uma boa razão a curto prazo para escolher a infraestrutura fechada. Ao mesmo tempo, em longo prazo se trabalha para melhorar as alternativas abertas. Se não pudermos ter em um momento dado uma infraestrutura aberta de primeira ordem para um objetivo concreto, devemos tomar medidas para tê-la mais adiante.
Do mesmo modo, para um propósito determinado em um momento dado, a melhor infraestrutura centralizada pode ser melhor que as alternativas descentralizadas. Em longo prazo, nenhuma plataforma centralizada pode ser melhor que um sistema de componentes interoperáveis, livre e de código aberto que opera em baixo padrão aberto. O ecossistema distribuído permite cada projeto e organização eleger os módulos que melhor se adaptam às necessidades locais. Permite aos usuários desenvolver novos módulos sem ter que construir uma alternativa a todo o sistema. Permite que a comunidade mundial amplie a pesquisa para satisfazer as necessidades globais sem ter que aceitar as limitações de uma plataforma central ou persuadir os responsáveis centralizados para que realizem mudanças completas. Estas possibilidades são importantes porque as plataformas e as infraestruturas, da mesma forma que as políticas e as estratégias, são mais eficazes quando se trata de limitações e culturas locais.
As instituições devem considerar a possibilidade de compartilhar os componentes da infraestrutura aberta. Todas as universidades deveriam fazem uso de um repositório de acesso aberto, mas não todas precisam do seu próprio repositório. Todos os editores de acesso aberto deveriam fazer uso de ferramentas de gestão e fluxo de trabalho, mas os editores necessitam ter suas próprias. Muitas instituições e nações precisam de portais de publicações de acesso aberto, mas não necessariamente precisam de um próprio, podem se beneficiar de portais nacionais ou regionais, como os existentes na Croácia, Etiópia, Finlândia, Grécia, Noruega, Sérvia, Espanha e América Latina. A infraestrutura compartilhada tem vantagens que as não compartilhadas não pode superar, incluindo os componentes não interoperáveis. Por exemplo, os repositórios de acesso aberto: é mais fácil para as universidades unir um repositório compartilhado que lançar repositórios separados. É mais fácil apoiar a mineração de textos e dados em um grande repositório compartilhado que em vários repositórios separados, e os resultados serão mais úteis. É mais fácil preservar um repositório grande e compartilhado que diversos repositórios separados. Como sabemos a partir dos grandes repositórios compartilhados como arXiv e PubMed Central, é mais provável que os pesquisadores que utilizam os repositórios como leitores vejam sentido de depositar como autores. A infraestrutura compartilhada pode ter características de vanguarda que a nova instituição pode permitir que se desenvolvam por si só.
Quando as instituições veem que não estão preparadas para implementar uma infraestrutura nova e aberta, deveriam tentar participar em conjunto com outras instituições. Quando você pode, deve ajudar a escrever o código. Poderiam pedir a suas equipes de desenvolvedores ou incentivar seus professores e estudantes para que participem. Se você não puder escrever o código, ajude os desenvolvedores a entender o que as instituições desejam e que podem ser usadas. A consulta prévia aos potenciais usuários poderá aumentar as probabilidades de adoção, uso, satisfação das necessidades locais e minimizará a perda de tempo, esforço e recursos.
Para ajudar a identificar a infraestrutura de pesquisa aberta, recomendamos a Global Coalition for Sustainability in Open Science Services ( SCOSS ); Invista em Infraestrutura Aberta ( IOI ); Conjunto de organizações comprometidas a seguir os Princípios de Infraestrutura Acadêmica Aberta ( POSI ); e Provedores de Infraestrutura de Comunicação Acadêmica ( SCIP ). Sem dúvida, nenhuma destas referências é uma fonte exaustiva e algo deliberadamente seletivo. Todas as organizações acadêmicas e de pesquisa devem buscar infraestruturas abertas que satisfaçam suas necessidades.
Práticas de avaliação da pesquisa
Recomenda-se reformar a avaliação da pesquisa para decisões de financiamento. E nas universidades e outros centros de pesquisa, também deve-se pensar nas decisões de contratação, promoção e permanência. Reformas podem eliminar os desincentivos ao acesso aberto e criar novos incentivos para o acesso aberto, sem limitar os temas, as conclusões ou o rigor da investigação, de modo totalmente compatível com a liberdade acadêmica e os mais altos padrões de qualidade.
As universidades deveriam abandonam os elementos que desincentivam o acesso aberto, como o Fator de Impacto das Revistas (JIF) e os rankings de revistas que dependem do JIF. O problema não é que as revistas de acesso aberto têm um JIF mais baixo que as revistas convencionais ( há evidência de que o acesso aberto aumenta as citações , também o JIF). O problema é que a mídia das revistas acessadas abertamente é mais jovem que a mídia das revistas não acessadas abertamente, e as revistas mais jovens cuidam do JIF com mais frequência que as mais antigas. Por esta mesma razão, os JIF discriminam as novas revistas (tanto de acesso aberto como aquelas sem acesso aberto) sobre temas emergentes, como a mitigação da mudança climática. Também discrimina as revistas não indexadas nos serviços comerciais devidos em seu idioma, localização geográfica ou afiliação institucional. A dependência do JIF para a avaliação também confunde uma métrica de impacto com uma métrica de qualidade, e confunde uma métrica das revistas com uma métrica dos artigos ou dos autores (veja também a recomendação 1.5 do BOAI-10 ).
Os comitês de avaliação da atividade de pesquisa raramente desestimulam deliberadamente o acesso aberto, por exemplo, porque se oponham ao mesmo. A desmotivação em geral, prevê os efeitos secundários de outras práticas, como o uso de classificações de revistas, medições de nível de revistas, compensações por publicações em revistas ou a falsa suposição de que todas ou a maioria de todas as revistas de acesso aberto são “revistas predatórias”. Assim, as reformas construtivas evitam os muitos obstáculos e nunca criam oposição ao próprio acesso aberto.
Eliminar os elementos que desestimulam o acesso aberto às práticas de avaliação da pesquisa é um grande passo adiante. Porém, apoiamos também novas práticas que incentivam o acesso aberto. Um bom exemplo é a prática pioneira da Universite de Liege (Bélgica) de avaliar os artigos do professor para sua promoção e permanência laboral apenas quando os artigos estão depositados no repositório institucional. Diversas universidades têm seguido esse exemplo, mas não suficientes. É claro que esta prática não afeta os temas, as conclusões ou a calibração da pesquisa (a recomendação 1.6 do BOAI-10 se apaia políticas semelhantes à Universidade de Lieja).
Quando os comitês de promoção e permanência em um posto de trabalho dos pesquisadores que iniciaram sua carreira publicam em revistas de alto prestígio e alto impacto, deve-se compreender que isto está desestimulando as publicações em revistas de acesso aberto. Também deveríamos entender o dilema dos pesquisadores que planejam seguir as políticas de acesso aberto das agências de financiamento. Dado que os dilemas podem ser resolvidos com base no acesso aberto pela via verde de depósito em repositórios de acesso aberto (ver pontos anteriores), os comitês de acesso aberto podem ser resolvidos e não deixar que os jovens pesquisadores descubram a opção por si mesmos ou como resolver o problema. Em qualquer caso, os comitês deveriam embasar suas avaliações na qualidade do trabalho do candidato, não nas revistas que publicam. Ao utilizar medições, deve-se usar medições em nível de artigo ou de autor, sem nível de revista.
Os comitês de avaliação da pesquisa das universidades e das entidades são incentivos em uma posição chave para criar e alterar os incentivos. Se não for utilizado este poder com cautela, pode ser um importante gargalho que aumenta ou diminui o acesso aberto. Ao utilizar com esmero, pode ser um importante acelerador do acesso aberto. Ao assumir que qualquer modificação das práticas de avaliação afeta a qualidade ou a liberdade acadêmica, estão confundindo as sugestões entre elementos distintos e independentes. As instituições de pesquisa devem trabalhar conscientemente para promover os objetivos e um posto de trabalho para promover a pesquisa aberta.
Abandonar os rankings de revistas e as medidas em nível de revista que requerem mudanças na cultura da pesquisa. Será necessário avaliar os trabalhos e as pessoas, não as revistas e as editoras. Será necessário passar das medições quantitativas às qualitativas. Requererá que os pesquisadores possam ver a artificialidade e a irrelevância das medições ao nível da revista e do motivo para abandona-las. Para julgar a qualidade, será fundamental que os acadêmicos deixem de depender das editoras, ou dos dados de resultados das decisões das editoras, e que assumam a responsabilidade de julgar o equilíbrio por si mesmos.
Taxas por artigos públicos (APCs)
Recomendam-se canais de publicação e distribuição inclusivos que não excluem os autores por motivos econômicos. Recomenda-se descartar as taxas por artigos publicados em acesso aberto (APCs). Há alternativas viáveis mas, sistematicamente são subestimadas, pouco contratadas, subvalorizados, subfinanciadas e subutilizadas. Recomendamos aprovar ao máximo estas alternativas para melhorar a equidade – Recomendamos inverter e explorar outras alternativas às APCs.
As APCs excluem os autores que não dispõem de financiamento para pagamento. Esta categoria inclui de forma desproporcional muitos autores do hemisfério Sul. Também exclui os pesquisadores independentes e os autores das instituições menos favorecidas ao Norte. As revistas baseadas em APCs excluem os autores por razões econômicas apenas, mas sim em relação à qualidade e importância do seu trabalho. Isso prejudica os proprios autores e os leitores que poderiam se beneficiar de seu trabalho. Prejudica a pesquisa ao excluir as perspectivas de autores, suas áreas de trabalho e regiões. Distorce o modo como as revistas refletem seus conteúdos pela adição de critérios de aceitação alheios aos méritos dos trabalhos apresentados.
As APCs são tão opacas e inescrutáveis como os preços das assinaturas. Os autores, as universidades, as bibliotecas, as agências de financiamento e outras partes interessadas em uma uma revista determinada com base no pagamento de APCs não podem saber que os gastos da revista cobren as APCs ou em que medida as APCs sobrepassam os gastos dela (no caso das grandes editoras, temos uma ideia das margens de benefícios anuais). As pessoas não conseguem saber se um APC se baseia no gasto histórico ou no prestígio da revista ou pelo fator de impacto; o que se cobra é o que a Editora crê que o mercado suportará e pretende preservar ou superar as margens de benefício anterior. Pela mesma razão, os descontos de APCs são opacos ou inescrutáveis, pois são completamente arbitrários. Entre outros prejuízos, a opacidade das APCs favorece sua inflação e promove pagamentos muito superiores aos serviços prestados. Ainda assim, mesmo que as APCs fossem mais baixas e mesmo que os editores sejam mais transparentes sobre o que cobrem as APCs (um objetivo de la coAlition S y the Fair Open Access Alliance ), da mesma forma recomendamos aproveitar as melhores alternativas às APCs. Inclua as APCs mais econômicas gestadas de forma transparente, não aquelas que constituem barreiras para os autores, e obstruem o progresso, pois há um sistema mais equitativo e inclusivo de comunicação científica.
A estes efeitos, não importa que as universidades e as agências de financiamento paguem a APC com o nome dos autores. Muitos autores não estão afiliados a instituições que podem ou desejam pagar essas taxas. Estes autores seriam excluídos por seus próprios recursos econômicos, senão por sua afiliação institucional, seria por outra variável irrelevante para a qualidade de seu trabalho. Os estudos mostram que os autores do Norte global são aqueles que melhor podem encontrar subvenções para as APC e os autores do Sul global os que menos encontram. Depender dos fundos institucionais para pagar as APCs beneficiam os autores que menos os necessitam e acentua as disparidades atuais. Claro, isto poderia alterar se mais institutos – em mais regiões e estratos econômicos- estiverem dispostas a pagar as APC. Mas, como as APCs trazem outros problemas, e como são desnessárias para a publicação das pesquisas, recomendamos que as instituições encontrem alternativas às APCs.
Quando as instituições apoiam o acesso aberto principalmente através do pagamento da APC, as revistas diamante adotam um incentivo perverso para começar a cobrar APCs. Da mesma maneira, e nas revistas de baixo APCs, há motivos para aumentá-los. Estas consequências agravam o dano causado pelos APCs aos autores que excluíram os leitores, que poderiam ter se beneficiado de seu trabalho. O dano aos leitores é global e o dano aos autores é desigual por disciplinas e regiões.
As APCs alimentam as revistas fraudulentas e predatórias, que prejudicam a todos os pesquisadores que enganam. Também dão má fama ao próprio acesso aberto, apesar de que todas as revistas predatórias são filhas do acesso aberto. A comunidade global de acesso aberto aborda atualmente este problema com diretrizes para revistas e medidas para educar os agentes implicados em relação à honestidade e à qualidade das revistas de acesso aberto. Estas estratégias úteis devem continuar. Mas, ao mesmo tempo, deveríamos acabar com as revistas predatórias mediante o abandono das APCs.
Sempre há alternativas às APCs: os repositórios de acesso aberto (rota verde) e as revistas de acesso aberto sem APCs (“diamante”). Como o acesso aberto verde e o diamante estão abertos aos leitores e aos autores, recomendamos pré-inicializar mais atenção, mais uso, mais financiamento e maior prioridade. A mudança de recursos do acesso aberto baseado em APCs ao acesso aberto “verde” e “diamante” dará espaço a mais vozes na pesquisa global sem reduzir a qualidade ou a abertura da pesquisa. Aumentará a qualidade da pesquisa ao comparar perspectivas anteriormente excluídas. Reduza o fluxo de dinheiro das instituições de pesquisa com fins lucrativos e melhore o controle da comunidade sobre a comunicação acadêmica.
Não estamos dizendo que artigos em periódicos de acesso aberto baseados na APC não sejam de acesso aberto no sentido pleno da declaração do BOAI. Eles são. Quando o acesso aberto baseado em APC cresce, o acesso aberto cresce. A tarefa aqui não é tornar as obras de acesso não aberto acesso aberto, mas parar de excluir autores por razões irrelevantes, parar de distorcer a pesquisa por meio dessas exclusões, parar de entorpecer a economia de acesso aberto, parar de pagar mais do que o necessário, parar de o fluxo de fundos limitados do setor acadêmico para o setor comercial, deixar de subordinar a sustentabilidade da pesquisa à sustentabilidade da renda dos editores e parar de consolidar um modelo de negócios com essas consequências. Por analogia: muitas instituições decidiram há muito tempo não pagar APCs em revistas híbridas, mesmo reconhecendo que artigos de acesso aberto em revistas híbridas de acesso aberto são de acesso aberto genuíno. A tarefa não era tornar o acesso aberto inoperável, mas parar de alimentar, incentivar e consolidar um modelo de negócios prejudicial.
Universidades e agências de financiamento que gastam quantias significativas em APCs deveriam investir em OA verde e diamante. Muitos periódicos de acesso aberto sujeitos ao modelo APCs e muitos periódicos de acesso não aberto, poderiam mudar para o acesso aberto diamante com a ajuda desse investimento, mesmo que não pudessem sem ele. Para periódicos que não puderam fazer a troca, autores e instituições devem continuar apoiando periódicos que não excluem autores por razões financeiras.
No passado, os editores se opunham ao acesso aberto verde porque o viam como parasita em periódicos revisados por pares e argumentavam que isso ameaçava sua sobrevivência. Ainda não se sabe que cancelamentos de assinaturas de periódicos foram causados pelo crescimento do acesso aberto verde (na verdade, os próprios editores mostraram que seus próprios aumentos de preços são a principal causa dos cancelamentos).). A objeção é menos comum hoje, em parte porque os editores que anteriormente a defendiam começaram a publicar seus próprios periódicos de acesso aberto com base em APCs (pelas mesmas razões, os editores descartaram amplamente sua antiga objeção de que APCs APCs padrões mais baixos para periódicos aceitarem mais artigos .) Mais importante ainda, a suposta ameaça de acesso aberto verde a periódicos revisados por pares não se aplica a periódicos de acesso aberto revisados por pares, com ou sem APCs, nem se aplica a preprints. Também não se aplica a periódicos que usam revisão por pares aberta, que exigem acesso aberto verde ou seu equivalente para manuscritos submetidos para publicação. Também não se aplica a revistas de sobreposição, que são revisados por pares e obscurecem a distinção entre acesso aberto verde e ouro usando a rede global de repositórios de acesso aberto como infraestrutura para sua distribuição. Apoiamos o crescimento em todos esses setores: periódicos de acesso aberto revisados por pares, preprints e overlay journals . Também apoiamos o projeto COAR Next Generation Repositories para aprimorar a rede global de repositórios de acesso aberto com novas camadas funcionais, incluindo revisão por pares, e ajudar a comunidade global de acesso aberto a aproveitar melhor o acesso aberto verde.
Mesmo em um mundo onde todos os artigos de pesquisa são publicados em periódicos de acesso aberto (com ou sem APC), ainda seremos verdes por muitas outras razões. Queremos acesso aberto verde para preprints , para marcar os tempos de depósito para novos artigos, para versões atualizadas após a publicação, para revistas de sobreposição, para preservação, para mineração de texto e dados e para resultados de pesquisas não publicados em periódicos, como conjuntos de dados, código-fonte, livros, teses, dissertações, artigos digitalizados e outros novos formatos. Gostaríamos que as políticas de acesso aberto de instituições e nações escolhessem repositórios em vez de periódicos como a modalidade preferida para acesso aberto. Isso inclui as políticas de instituições que não querem limitar a liberdade dos autores de escolher o periódico para onde enviar seus trabalhos e políticas que permitem que jovens pesquisadores cumpram qualquer política de acesso aberto de uma agência que financia suas pesquisas, e por sua vez pode se submeter a um comitê de avaliação tradicional para promoção e permanência. Finalmente, gostaríamos de ver o acesso aberto verde como um canal maduro e amplamente aceito para pesquisa aberta caso outros canais, incluindo periódicos de acesso aberto baseados em APC, falhem ou se tornem menos atraentes por qualquer motivo, incluindo um boicote por parte dos autores ou por não ser economicamente sustentável.
Em muitas regiões e disciplinas, o acesso aberto por meio de periódicos com APCs tem sido o tipo de acesso aberto mais conhecido. De fato, muitas partes interessadas ainda afirmam ou assumem que todo acesso aberto é ouro de acesso aberto em periódicos com APCs. Esse mal-entendido persiste apesar do fato de que os repositórios de acesso aberto precedem os periódicos de acesso aberto e coexistem com eles desde sua criação. Ele persiste mesmo que os periódicos de acesso aberto com APCs sejam a minoria dos periódicos de acesso aberto revisados por pares (em 18 de janeiro de 2022, apenas 30,4% dos periódicos listados no Open Access Journal Directory Open cobravam APC, embora em 2020 65% dos itens publicados em periódicos OA foram publicados em periódicos com APCs). Esse mal-entendido causa danos. Os autores que precisam cumprir as políticas de acesso aberto verde (que exigem depósito em um repositório) pensam erroneamente que precisam cumprir as políticas de acesso aberto ouro (que exigem submissão a um determinado tipo de revista). Autores que desejam tornar seu trabalho de acesso aberto estão errados em considerar apenas periódicos baseados em APC. Se eles não conseguem financiamento para pagar as APCs, eles concluem erroneamente que não podem tornar seu trabalho de acesso aberto. As instituições que desejam apoiar periódicos de acesso aberto limitam-se erroneamente a periódicos que usam APCs. Periódicos de assinatura considerando mudar para acesso aberto erroneamente se limitam a considerar modelos de negócios baseados em APCs e não consideram outras opções. Aqueles que tentam calcular quanto custaria à comunidade científica global se todos os artigos do mundo fossem publicados em periódicos de acesso aberto revisados por pares cometem o erro de limitar a análise ao que a comunidade gastaria em APCs. As pesquisas sobre as atitudes dos autores em relação ao acesso aberto são erroneamente limitadas a perguntas sobre periódicos de acesso aberto com APCs. Todos, incluindo aqueles que apoiam os APCs, devem corrigir esses mal-entendidos. Em suas próprias comunicações, eles devem falar claramente. O acesso aberto pode ser obtido por vários meios, incluindo repositórios, não apenas por meio de periódicos. Os periódicos de acesso aberto adotam diferentes modelos de negócios, não apenas o de APCs.
Qual é a melhor maneira de aproveitar o acesso aberto verde? Deveria haver um maior número de políticas institucionais de acesso aberto apenas acesso aberto verde ou ser neutra em relação a qual caminho de acesso aberto seguir (verde ou ouro), o que permitiria ao autor escolher o canal para conformidade. A maioria das políticas de acesso aberto das universidades defende o verde, o que aplaudimos. As políticas de acesso aberto da maioria das agências de financiamento ainda são apenas verdes, mas há um número crescente delas favorecendo a rota do ouro. Alguns, como o Plano S e a política do UKRI, são neutros em termos de rota de acesso aberto, com opções para sua conformidade de um tipo ou de outro. Outra forma de aproveitar melhor o acesso aberto verde é as universidades negociarem com as editoras o depósito automático de manuscritos em seus repositórios institucionais. Os países devem negociar com os editores o depósito automático em repositórios nacionais ou regionais. As instituições de pesquisa devem apoiar periódicos de sobreposição que usam repositórios de acesso aberto como fonte de conteúdo selecionado. Cada vez mais, universidades e agências de financiamento devem adotar políticas de retenção de direitos autorais, para permitir o acesso aberto verde quando os editores não o apoiam e para apoiar o acesso aberto verde irrestrito e licenças abertas, caso as instituições não tenham os direitos necessários. Alterações no estilo Taverne às leis de direitos autorais devem ser adotadas que produzam os mesmos efeitos ou fortaleçam as emendas existentes para remover restrições e embargos. Instituições e nações que desejam acesso aberto imediato e licenças abertas precisam entender que o acesso aberto verde pode atender a essas condições. As universidades devem empreender esforços sistemáticos e adequadamente financiados para hospedar os resultados da pesquisa em seus repositórios institucionais. As universidades que pagam por APCs (por meio de acordos de publicação ou fundos especiais) devem redirecionar parte desse dinheiro e seus orçamentos de pagamento de assinaturas para os mesmos esforços para alcançar o acesso aberto verde. Universidades e agências de financiamento que incentivam ou exigem ouro de acesso aberto e acharem difícil pagar APCs para todos os autores sujeitos às suas políticas, devem incentivar ou exigir o acesso aberto verde e investir na coleta dos trabalhos da instituição em um repositório de acesso aberto. Autores e instituições devem privilegiar periódicos que utilizem licenças abertas e não exijam direitos exclusivos, para que mais artigos e mais versões possam ser depositados em seu repositório. Autores e instituições devem entender que a versão aceita dos manuscritos geralmente tem o mesmo texto da versão eventualmente publicada. Por fim, as universidades e seus patrocinadores devem ajudar os pesquisadores em início de carreira a cumprir as políticas de acesso aberto pelo caminho verde.
Como devemos aproveitar melhor o diamante Open Access? Universidades, agências de financiamento e governos devem ir além do apoio moral e fornecer apoio financeiro para o Acesso Aberto Diamante. Eles poderiam contribuir e investir diretamente nos periódicos Open Access Diamond gerenciados ou editados por sua comunidade acadêmica. Eles poderiam apoiar iniciativas de Acesso Aberto de diamantes, como a Biblioteca Aberta de Humanidades , OPERAS e Redalyc-AmeliCA . Ou eles poderiam apoiar o Diamond Open Access indiretamente por meio de organizações como a Fair Open Access Alliance ( FOAA ), Free Journal Network ( FJN ), JISC, LingOA ou o Programa de Investimento da Comunidade de Acesso Aberto ( OACIP ). Eles poderiam adotar as recomendações do Plano de Ação Diamond Open Access . Universidades e agências de financiamento que pagam APCs devem redirecionar quantias crescentes desse dinheiro para apoiar periódicos diamante de acesso aberto. As bibliotecas devem destinar fundos de seus orçamentos de taxas de assinatura para o mesmo propósito. Aqueles que fornecem suporte financeiro para pagar por APCs devem fornecer pelo menos o mesmo suporte financeiro para periódicos de Acesso Aberto sem APCs. A comunidade acadêmica e os editores de periódicos de acesso aberto Diamond devem ajudar a mostrar as várias formas como as revistas diamante obtêm recursos para sua sustentabilidade. Assim como os periódicos pay-per-subscription frequentemente exploram a possibilidade de se tornarem periódicos de acesso aberto e os periódicos híbridos frequentemente exploram a possibilidade de se tornarem periódicos de acesso aberto não híbridos, os periódicos de acesso aberto com APCs também deveriam explorar a possibilidade de se tornarem periódicos abertos não híbridos. para se tornarem revistas de acesso aberto Diamond. Os periódicos de acesso aberto Diamond existentes devem apoiar essa possibilidade e colaborar com os periódicos que consideram esse modelo para explicar por que adotaram o acesso aberto sem APCs e como isso funciona na prática.
Acordos de leitura e publicação
Quando gastamos dinheiro para publicar trabalhos de acesso aberto, devemos lembrar os objetivos para os quais o acesso aberto é o meio e não o fim. Devemos favorecer modelos de publicação que beneficiem todas as regiões do mundo, que sejam controlados por organizações acadêmicas e sem fins lucrativos, que evitem concentrar a produção científica de acesso aberto em periódicos comercialmente dominantes e que evitem modelos entrincheirados que conflitem com esses objetivos. Recomendamos não fazer acordos de “compensação”, “ler e publicar” ou os chamados acordos “transformativos”.
Nos referiremos a esses acordos coletivamente como acordos de “leitura e publicação”, embora reconheçamos que existem muitas variações sobre esse mesmo tema . Não usamos o termo “transformativo” porque não é autoexplicativo, porque vem antes de um termo útil que poderia ser aplicado a outras iniciativas transformacionais ou transformadoras, e porque é mais um termo honorífico do que descritivo.
Em primeiro lugar, observamos que a opinião de nossos respondentes está dividida em relação a esses acordos. Alguns os apoiam e outros não.
Os acordos de leitura e publicação têm o efeito benéfico de aumentar o número de artigos de acesso aberto. Este crescimento é apreciado, mas nos preocupa que se torne um objetivo prioritário em detrimento dos objetivos subjacentes. Esses acordos dependem do modelo de pagamento das APCs e o consolidam ainda mais. Portanto, eles crescem o corpus de conteúdo de acesso aberto por meio de métodos que excluem alguns autores. Queremos que o corpus de acesso aberto cresça com métodos que incluam todos os autores, independentemente de sua afiliação institucional ou circunstâncias econômicas. Queremos reorientar os objetivos do acesso aberto em si. Por fim, acreditamos que esses acordos são insustentáveis, pagando mais do que o necessário e colocando o crescimento de curto prazo antes do crescimento de longo prazo.
Os defensores costumam dizer que esses acordos isentam os APCs. Mas isso é enganoso. Embora os autores não paguem APCs nos periódicos conveniados e não precisem buscar financiamento para custear os APCs, as negociações acabam determinando o custo que a instituição deve assumir. Esses custos suportados pela instituição são os APCs ou seu equivalente para fins práticos. Em vez de eliminar os APCs, esses acordos preveem que as instituições os paguem antecipadamente em nome dos autores. Esse arranjo é uma melhoria em relação às APCs que são pagas diretamente pelos autores, mas ainda traz as outras desvantagens das APCs. As APCs pré-pagas sob esses acordos são tão opacas e inescrutáveis quanto as APCs endereçadas diretamente aos autores. O mesmo vale para as isenções e descontos que as APCs supostamente oferecem. Podemos saber os valores que ambas as partes usaram para o cálculo, mas não sabemos quais despesas elas cobrem ou em que medida excedem os custos para a editora. Em alguns casos, os acordos concedem à universidade um número ilimitado de isenções. Nesses casos, o APC ou seu equivalente diminui de preço à medida que aumenta o número de autores abrangidos pelo acordo que publicam nos periódicos incluídos nele. Isso é melhor do que as alternativas sem essa opção, mas não resolve outros problemas desse modelo e até agrava o problema de direcionar a maior parte da produção científica para o setor editorial comercialmente dominante. Exclui autores de instituições que não podem arcar com esses acordos. Esses acordos também reduzem os incentivos para autores ou instituições favorecerem periódicos com APCs mais baixas ou sem APCs (lembre-se que estes são a maioria de todos os periódicos de acesso aberto), e para as agências de financiamento pagarem por APCs junto com as universidades.
O custo do APC de um periódico pode ser alto porque está atrelado a altos gastos, por exemplo, em periódicos altamente seletivos. Nesses casos, o problema não é que o APC supera em muito o custo de produção, mas também que a taxa é muito maior do que o necessário. O problema é que é maior do que seria se o mesmo artigo fosse publicado em outro lugar, por exemplo, em um periódico com APC menor, em um periódico sem APC ou em um repositório de acesso aberto. Esse problema é intrínseco aos periódicos de acesso aberto com APCs, mesmo aqueles com menor custo de produção e APCs. Deve haver uma justificativa especial e convincente para pagar uma taxa para compartilhar pesquisas quando a mesma pesquisa pode ser compartilhada sem pagamento. Quando o autor pode publicar o mesmo artigo em outro lugar, a justificativa não pode ser que pagar pela publicação melhora a qualidade do artigo. O pagamento também não melhora a qualidade do artigo quando o motivo é a marca, o prestígio ou as métricas da revista. Essas taxas não são pagas por melhor qualidade, mas pela percepção de melhor qualidade. Entendemos que a progressão na carreira pode depender dessa percepção. Mas esse é um problema a ser resolvido, não uma realidade imutável à qual se adaptar. A solução mais equitativa, sustentável e academicamente honesta é que os conselhos de revisão de pesquisa prestem menos atenção ao local de publicação e mais à qualidade da pesquisa em si (consulte a recomendação 2). Esses comitês, acima de qualquer outra parte interessada, eles devem se concentrar na qualidade sobre o prestígio, quando os dois diferem. Independentemente de os APCs estarem intimamente ligados aos custos de produção, pagá-los significa desistir da luta para promover modelos de escala sustentável para todas as disciplinas, regiões e estratos econômicos.
Os periódicos sob esses acordos continuam a cobrar assinaturas e tornam apenas alguns de seus artigos OA. São revistas híbridas. O pagamento de APCs em periódicos híbridos é desencorajado, como muitas universidades e agências de financiamento decidiram há muito tempo. Um dos motivos é aumentar o retorno dos recursos destinados às APCs. Outra é que os periódicos híbridos cobram APCs médias mais altas do que os periódicos de acesso totalmente aberto, embora as revistas híbridas também se beneficiem da receita de assinaturas. Outra é que os periódicos híbridos costumam cobrar o dobro (cobram duas vezes por seus artigos de acesso aberto, uma vez por meio de assinaturas e outra por meio de APCs). Revistas de acesso totalmente aberto ou não-híbridas não podem cobrar duas vezes pela mesma coisa. No entanto, o principal motivo é evitar criar incentivos perversos para os autores e periódicos que recebem o dinheiro. Pagar APCs em periódicos híbridos é pagar para que os periódicos permaneçam híbridos. Ao pagá-los, faz com que resistam à conversão de revistas de acesso totalmente aberto que muitas instituições pretendem e preveem quando assinam os acordos.
Os promotores desses acordos costumam prever que os periódicos incluídos neles passarão de acesso aberto híbrido para acesso aberto total ou acesso aberto não híbrido. No entanto, não estamos vendo muitas conversões, nem há planos de conversão dos editores. Também não estamos vendo acordos que tornem a conversão uma disposição executória no contrato. Ao contrário, há incentivos para que os periódicos incluídos nesses acordos permaneçam híbridos e resistam à conversão. Tenha em mente, no entanto, que mesmo se começarmos a ver conversões de periódicos híbridos para periódicos de acesso totalmente aberto, isso não será um progresso significativo se novos periódicos de acesso aberto contarem com APCs.
Esses acordos tendem a ser estabelecidos entre os maiores e mais ricos editores, direcionando grande parte da nova literatura de acesso aberto para eles mesmos. Isso agrava o efeito de monopólio do atual cenário editorial e exclui os periódicos de acesso aberto diamante (a maioria, lembre-se), periódicos de acesso aberto nascidos, periódicos de acesso aberto completo ou não híbrido e aqueles que podem ser menores, sem fins lucrativos, menos caro para instituições de pesquisa, ou alguma combinação destes. Nesse sentido, esses acordos não apenas fortalecem o modelo de APCs, mas também fortalecem o atual sistema de prestígio dos periódicos e dos afetados por esse sistema. Além disso, esses acordos tendem a ser feitos pelas maiores e mais ricas universidades, expandindo, ao invés de reduzir,
O apoio financeiro que recomendamos às revistas de acesso aberto Diamante difere em dois aspectos do apoio recebido pelas revistas de acesso aberto, proporcionado por estes acordos. Em primeiro lugar, os periódicos de acesso aberto Diamond não são periódicos híbridos. Em segundo lugar, os periódicos de acesso aberto Diamond não cobram de nenhum autor pela publicação, e não apenas daqueles afiliados às instituições participantes dos acordos.
Como apoiamos novos projetos, estamos dispostos a mudar nossa posição se esses acordos levarem a conversões de revistas que resolvam nossas objeções. Nesse sentido, é animador que instituições e editoras estejam desenvolvendo novas alternativas sobre o tema.
15 de março de 2022
Tradução feita por Juan Pablo Alperin, Arianna Becerril-García, Saray Córdoba, Erin McKiernan e Remedios Melero
Tradução para o espanhol de Juan Pablo Alperin, Arianna Becerril-García, Saray Córdoba, Erin McKiernan e Remedios Melero
Esta é uma reprodução da matéria de autoria de André Vieira . 22 de fevereiro de 2022
Este relatório apresenta uma coleção de sete estudos de caso descrevendo como as competências FAIR estão a ser abordadas através de programas de formação. Estas boas práticas oferecem exemplos de integração bem sucedidos da Gestão de Dados de Investigação (GDI) e das competências dos princípios FAIR relacionadas com dados nos currículos e formação das instituições de ensino superior, a fim de oferecer uma perspectiva atualizada sobre como estas competências estão a ser implementadas pelas instituições de ensino superior.
Oferece às instituições de ensino superior elementos de inspiração e exemplos práticos de como se pode abordar a necessidade de mais competências em matéria de GDI e dados FAIR a serem lecionadas a nível de licenciatura, mestrado e doutoramento. Fá-lo através da análise de fatores externos e internos, passos para a implementação, capacidade investida e impacto alcançado pelas boas práticas.
Este relatório foi desenvolvido no âmbito do projeto FAIRsFAIR e está disponível em: https://doi.org/10.5281/zenodo.5940099, que visa desenvolver soluções práticas para apoiar a implementação e utilização dos princípios dos dados FAIR ao longo do ciclo de vida dos dados de investigação.
Visão global dos 7 estudos de caso
Organização
Nome da iniciativa
Tipo de iniciativa
Público-alvo
U Bremen Research Alliance Alemanha
Data Train programme
Programa de formação
Estudantes de Doutoramento
Universidade NOVA de Lisboa Portugal
Research Data Management course
Curso
Estudantes de Doutoramento
TU Wien Áustria
Center for Research Data Management and Data Stewardship course
Unidade institucional dedicada à GDI e curso
Comunidade universitária e estudantes de Mestrado (Curso)
Tampere University Finlândia
Managing Research Information course and RDM: survey and interview data course
Cursos
Estudantes de Mestrado
swissuniversities Suíça
Open Science programme
Sistema de financiamento nacional
Instituições de ensino superior
Universidade do Minho Portugal
O Essencial da Gestão de Dados de Investigação (MOOC)
MOOC
Estudantes de Doutoramento e outros Investigadores
University of Cape Town África do Sul
Variety of training courses on RDM and FAIR data-related topics
Programas de formação
Comunidade universitária
Para saber mais sobre estas iniciativas de formação, consulte a secção de estudos de caso do relatório (https://doi.org/10.5281/zenodo.5940099)
Principais conclusões
Âmbito e objetivos
Todos os estudos de caso partilham a necessidade de apoiar a aquisição de competências de dados FAIR em todos os níveis institucionais. No entanto, os investigadores de doutoramento continuam a ser vistos como uma categoria “prioritária” para se dotarem de competências relacionadas com dados.
Interdisciplinaridade como característica comum a todos os estudos de caso mas tem os seus limites.
Diversidade de responsáveis pela implementação da formação em GDI e dados FAIR:
Agentes externos: a emergência de novas políticas e requisitos de financiamento a nível nacional e europeu.
Agentes internos: compromisso dos profissionais (por exemplo, bibliotecários e membros do pessoal de apoio à investigação) de melhorar a formação em dados FAIR e a presença de políticas institucionais que regulem as práticas de dados de investigação.
Implementação
Importante combinar abordagens top-down e bottom-up para assegurar a eficácia e sustentabilidade a longo prazo das novas atividades de formação de dados FAIR.
Suporte e recursos
Importância de financiamento e recursos humanos dedicados.
Um financiamento consistente pode assegurar a continuidade das atividades de formação a longo prazo e ajudar a alcançar objetivos e marcos também relacionados com estratégias institucionais.
Impacto
Necessidade de ir além do modelo tradicional de avaliação para fazer um balanço completo do impacto e influência alcançados pela iniciativa de formação.
A formação é importante mas não suficiente. Um conjunto diversificado de desafios ainda impede estudantes e investigadores de aplicar os princípios FAIR, incluindo a falta de um sistema de incentivos e recompensas.
Encontrar sinergias com outras prioridades na agenda institucional e nacional (por exemplo, ética e integridade da investigação, digitalização) pode ser um instrumento para não replicar esforços.
Ter uma estratégia e objetivos claros é fundamental para enfrentar os desafios que podem surgir e transformá-los em oportunidades.
Recomendações
Promover o envolvimento do pessoal de investigação e suporte e reforçar a capacidade em todos os níveis institucionais.
Necessidade de promover o intercâmbio entre líderes e profissionais, levando à definição de novas estratégias institucionais para apoiar a formação sobre dados FAIR.
“Everybody should be a data steward” e necessidade de toda a comunidade universitária se capacitar com as competências e práticas dos dados FAIR.
Desenvolver e articular políticas, infraestruturas e formação de competências para se reforçarem mutuamente
Políticas, infraestruturas e formação como três pilares principais de uma estratégia global destinada a transformar os princípios FAIR uma realidade.
Estar consciente das oportunidades a nível europeu e nacional e integrá-las nas estratégias institucionais
As universidades são atores chave na formação da próxima geração de profissionais de dados.
No entanto, devem trabalhar isoladamente e os seus esforços devem ser sustentados por novos quadros políticos e orientações a nível nacional e europeu.
O Directory of Open Access Books (DOAB) – iniciativa lançada em 2012 inspirada no Directory of Open Access Journals (DOAJ) – indexa livros de acesso aberto revisados pelos pares e fornece informação sobre seus publishers. Hoje celebramos um marco para a comunidade de acesso aberto ao ultrapassarmos o limite de 50.000 livros de acesso aberto, enquanto observamos como podemos, coletivamente, continuar nossos esforços para que os livros de acesso aberto prosperem.
Ao mesmo tempo, as editoras tradicionais estão implementando novas abordagens, que evitam o uso de taxas de processamento de livros, possibilitando a publicação de seus livros em acesso aberto. Editoras como a MIT Press, que introduziu um novo modelo denominado Direct to Open (D2O) em 2021, resultando no lançamento de toda a sua lista de monografias da Primavera de 2022 e coleções editadas em acesso aberto; a University of Michigan Press com seu programa Fund to Mission e a Central European University Press e a Liverpool University Press usando o modelo Opening the Future, desenvolvido pelo projeto COPIM.
“O DOAB se tornou uma plataforma essencial para novas e menores editoras de acesso aberto para aumentar a visibilidade de seus livros e garantir que eles apareçam em catálogos de bibliotecas, ajudando assim editoras como a Open Book Publishers e nossos colegas do consórcio ScholarLeda crescer e se tornar mais estabelecidas no cenário editorial acadêmico. Da mesma forma, apoiou as editoras mais tradicionais à medida que dão seus primeiros passos na publicação de livros de acesso aberto com novos modelos de financiamento, como Opening the Future.
O DOAB é um parceiro essencial do projeto COPIM (Community-led Open Publication Infrastructures for Monographs) na construção de infraestrutura de propriedade da comunidade, como o Open Book Collective e o sistema aberto de gerenciamento de metadados Thoth, que buscam encontrar novas maneiras de compartilhar o trabalho de publishers de livros de acesso aberto inovadoras e forjar parcerias entre estas editoras e bibliotecas universitárias para apoiar um ecossistema de conhecimento maior e mais aberto.” Rupert Gatti, cofundador e codiretor da Open Book Publishers.
Embora tenhamos visto um crescimento encorajador do DOAB – agora tendo atingido esta marca de 50.000 livros de acesso aberto – bem como novos modelos e experimentação com livros de acesso aberto, o caminho a percorrer para todos nós ainda é longo, pois a maioria dos livros acadêmicos ainda são publicados com acesso restrito. Esforços adicionais, como o Open Book Collective e o investimento coordenado para melhorar a transição para livros de acesso aberto, são muito necessários.
Webinar: Facilitando a geração de relatórios e aumentando a visibilidade da saída de publicação de acesso aberto – um webinar de instruções dos participantes de editores do OA Switchboard
Em inglês: Webinar: Making reporting easy and increasing visibility of open access publication output – a how-to webinar from OA Switchboard publisher participants
Data: quarta-feira, 20 de abril de 2022 Horário: 15h às 16h15 Reino Unido (14h às 15h15 UTC)
Junte-se a nós para conhecer três estudos de caso de editores sobre como se conectar ao OA Switchboard para facilitar a geração de relatórios e aumentar a visibilidade da saída da publicação OA. Nossos palestrantes abordarão as diferentes opções de interação com o OA Switchboard (manual, via API ou conector personalizado), ilustradas por suas próprias experiências da vida real e lições aprendidas. Nosso parceiro de tecnologia adicionará informações básicas e práticas recomendadas em todos os editores operacionais no OA Switchboard, bem como com tendências futuras que estão se formando.
Palestrantes
Wendy Patterson & Christian Lange , Beilstein-Institut
Matthew Day , Cambridge University Press & Assessment
Frederick Atherden & Kamruj Jaman , eLife
Ivo Verbeek , Appetence/ELITEX
Yvonne Campfens, equipe distribuição OA
Observe que este webinar é gratuito e aberto a todos, graças ao apoio de nossos patrocinadores da série de webinars de 2022 , e uma gravação do webinar foi disponibilizada logo após o evento.
Biografias dos Painelistas
Fred Atherden
Fred ingressou na eLife em 2018 e é chefe de operações de produção. Antes de ingressar na eLife, Fred trabalhou na Bloomsbury Publishing, onde cuidou do fluxo de trabalho para entrega de conteúdo digital, e na Cambridge University Press.
Yvonne Campfens tem mais de 25 anos no setor editorial e de serviços relacionados, com mestrado em econometria aplicada pela Universidade de Amsterdã (1993). No início de sua carreira, ela ocupou um cargo editorial na Elsevier Science e, posteriormente, vários cargos no Swets Subscription Service, incluindo relações com editores e como parceira de negócios da ALPSP na gestão da ALJC (ALPSP Learned Journals Collection). De 2007 a 2012, ela liderou a integração de parceiros de publicação de sociedades eruditas na Springer Nature e foi co-fundadora do Código de Prática da TRANSFER. Depois de administrar o negócio educacional/profissional de língua holandesa na Springer Media por três anos como diretora administrativa, ela retornou ao grupo de pesquisa internacional da empresa recém-fundida (Springer Nature) em 2015, onde trabalhou em todas as divisões da Springer Nature Research.
Em 2018 iniciou seu próprio negócio de consultoria e em 2020 foi gerente de projetos da OA Switchboard, uma iniciativa supervisionada pela Open Access Scholarly Publishers Association (OASPA). A partir de 2021, o OA Switchboard passa para o estágio operacional e será executado a partir do recém-fundado Stichting OA Switchboard, para o qual Yvonne atua como Diretora Executiva.
Dia de Mateus
Matthew é chefe de Políticas e Parcerias de Pesquisa Aberta na Cambridge University Press, coordenando e desenvolvendo políticas, práticas e capacidades de Pesquisa Aberta trabalhando com partes interessadas externas e dentro da CUP. Ele tem 20 anos de experiência na indústria editorial, tendo ocupado cargos editoriais e gerenciais na Garland Publishing, BioMed Central, Nature Publishing Group, além de alguns anos na empresa de tecnologia Wolfram Research. Além de ter grande interesse na publicação de acesso aberto para livros e periódicos, Matt tem interesse de longa data no papel dos editores na disseminação e preservação de dados de pesquisa acadêmica e no papel dos computadores no processamento do conhecimento.
Kamruj Jaman Tendo ingressado na eLife há três anos, Kam é o Controlador Financeiro da eLife. Nesse período, Kam gerenciou a transição de uma função financeira amplamente terceirizada para uma totalmente interna, introduziu uma série de melhorias nos sistemas e supervisionou várias auditorias bem-sucedidas.
Christian Lange
Christian Lange é editor científico do Diamond Open Access Beilstein Journals. Por mais de dez anos ele tem sido feliz por fazer parte da comunidade Open Science. Além de seu trabalho como editor, ele também é o elo entre a equipe editorial e os desenvolvedores de software quando as ideias da Open Science são traduzidas em soluções técnicas funcionais. A integração total da API REST Open Access Switchboard no fluxo de trabalho do Beilstein Journals é um exemplo disso. Christian possui diploma em química e doutorado em física de materiais.
Wendy Patterson é membro do conselho de administração do Beilstein-Institut , onde atua como diretora científica. Ela recebeu vários diplomas no campo da física, culminando em um doutorado em óptica na Universidade do Novo México. Ela continuou a pesquisa de pós-doutorado nas áreas de nanotecnologia e materiais para conversão e armazenamento de energia no Centro de Tecnologias Emergentes de Energia e na Universidade de Regensburg. Preocupada com a direção que a publicação acadêmica tomou e seu impacto sobre os acadêmicos, ela se juntou ao Beilstein-Institut sem fins lucrativos em 2014 para contribuir com seus periódicos de acesso aberto diamante. Ela também é membro do conselho da Crossref e da Free Journal Network, ambas entidades sem fins lucrativos que prestam serviços para a comunidade acadêmica.
Ivo Verbeek
Ivo é um Solution Provider em Publicação, com foco nas atividades de publicação em Acesso Aberto e na transição para Acesso Aberto. As soluções incluem integração de sistemas, serviços e ferramentas de código aberto gratuitas. Ivo é Diretor de Appetence e representa o centro de desenvolvimento ELITEX na Holanda.
O primeiro Plano Nacional de Ciência Aberta da França 2018-2021 levantou questões sobre o papel das bibliotecas e centros de documentação e o roteiro a seguir para adaptá-lo à realidade da pesquisa. Em fevereiro de 2021, quatro gerentes gerais de educação, esporte e pesquisa prepararam um relatório dirigido a Frédérique Vidal, ministro francês do Ensino Superior, Pesquisa e Inovação. 2
As reflexões neste relatório são baseadas em entrevistas e pesquisas, com três objetivos principais:
Qual o papel das bibliotecas universitárias após o Plano Nacional?
O que as bibliotecas contribuem para a ciência aberta em termos de conscientização, treinamento, coordenação e realizações concretas?
Que efeitos terá a aplicação do Plano em termos de organização, postos de trabalho, competências, projetos e sinergias?
A primeira seção do relatório apresenta uma definição e um estado da arte da ciência aberta. Dentro da revisão dos conceitos, vale destacar um quadro-resumo de um possível plano de ação, com recomendações e áreas envolvidas (p. 14), com base no relatório da Open Science Policy Platform, escrito por um grupo de especialistas comissionados pelo a Comissão Europeia .
A segunda e terceira seções fornecem a visão teórica genérica das ações específicas que estão sendo realizadas nas universidades francesas e oferecem um catálogo que pode servir de modelo para as demais. A pesquisa, realizada com 70 instituições (bibliotecas universitárias ou centros de documentação), mostra que as bibliotecas participam do desenvolvimento de políticas e mandatos de ciência aberta, embora essa participação seja muito desigual e pouco definida.
Sensibilização e formação No caso das atividades realizadas, é evidente que a ciência aberta alarga o campo de intervenção das bibliotecas e mobiliza novas competências. Conscientização e treinamento são os dois pontos fortes das bibliotecas universitárias que valorizam. Na pesquisa, é surpreendente que existam bibliotecas que respondem que não realizam nenhuma ação nesse sentido, nem oferecem nenhum tipo de guia ou material para seus usuários.
Recomenda-se ampliar a formação em gestão de dados de pesquisa, não apenas o depósito de dados abertos em repositórios, e oferecer treinamento por meio de diferentes canais além do formato presencial. 3 É muito importante que, antes de pedir à equipe de pesquisa para abrir seus dados de pesquisa, possamos convencê-la das vantagens de uma gestão eficiente.
Observemos uma situação semelhante na Espanha em termos de dedicação de esforços na formação de pessoal, na expectativa de ter que lidar com cada vez mais consultas e ações sobre ciência aberta.
Destaco o quadro de dedicação (ETI) do pessoal aos serviços de apoio à investigação, 21% dos centros dedicam cerca de 10% do seu pessoal. Garanto que veremos como esse número aumentará nos próximos anos. Mostra também que muitas organizações estão em um momento de reestruturação, ou repensando perfis e funções.
O relatório conclui com uma sugestão muito clara sobre a necessidade de melhorar o défice de recursos humanos e competências técnicas.
Em momentos de mudança radical, nós profissionais valorizamos saber o que outras instituições estão fazendo, alguns diriam para nos refletir, mas eu diria claramente para copiar e tentar melhorar o modelo, o roteiro, a ação… cultura.
Competências profissionais O texto menciona de forma geral as competências profissionais que os profissionais de biblioteca devem ampliar:
Conhecimento do ecossistema de comunicação científica: especialmente das plataformas para publicar e depositar. Controle do “pagar para ler”. Pretende-se aumentar as competências na identificação, descrição e gestão de dados de investigação.
Competências informáticas e técnicas: estatísticas, bases de dados, repositórios, API…
Recomendações Finalmente, chegamos à parte mais interessante do relatório. A página 7 contém um resumo das diferentes recomendações, também intercaladas no texto, onde são explicadas e justificadas com base na dinâmica observada em outros países, na pesquisa realizada ou no que os autores analisaram nas diferentes visitas e entrevistas com instituições.
Para autoridades nacionais
1. Desenvolver um plano nacional de formação em ciência aberta para o pessoal de investigação, pessoal de biblioteca e estudantes de doutoramento, após levantamento das necessidades das bibliotecas e instituições. Estabeleça diferentes rotas adaptadas a diferentes níveis. Leve em conta o amplo acesso, oferecendo abordagens híbridas, presenciais e remotas, e fórmulas mistas, combinando públicos de pesquisa e bibliotecários.
2. Encarregar à Agência Bibliográfica do Ensino Superior a tarefa de promover o desenvolvimento e coordenar a implementação de um plano nacional para o desenvolvimento de identificadores.
Na minha opinião, seria importante que cada país elaborasse uma análise dos principais identificadores de ciência aberta em cada campo (publicações, dados, organizações, pessoas…) e incentivasse seu uso.
para organizações
3. Repensar o papel do apoio à pesquisa tanto nas bibliotecas quanto no restante da instituição para obter clareza do ponto de vista do pesquisador e eficiência no uso dos recursos humanos. Desenvolver o apoio à ciência aberta, incluindo-a nos planos estratégicos da organização e aumentar o número de empregos permanentes atribuídos a esta missão nas bibliotecas.
O relatório trata das diferentes estruturas de serviços de apoio à pesquisa, ciência cidadã em relação às bibliotecas e também recursos educacionais abertos.
4. Organize o apoio aos pesquisadores para a ciência aberta em uma única janela. O serviço, que incluirá membros de diferentes áreas, deverá ser coordenado pela biblioteca.
5. Desenvolver uma estratégia institucional de gestão de dados de investigação baseada numa oferta de serviços básicos constituídos pela sensibilização e formação de doutorandos e investigadores em gestão de dados, independentemente da disciplina. Incluir um aumento progressivo de recursos e serviços de acordo com os objetivos estabelecidos pela instituição.
6. Reunir recursos e fomentar a colaboração entre os diferentes atores da edição científica, incluindo bibliotecas e serviços de publicação universitária.
7. Reforçar e aplicar sistemas de incentivo ao depósito nos repositórios do texto completo (não referências bibliográficas).
8. Incentivar o pessoal de pesquisa e o pessoal da biblioteca a colaborar em projetos de pesquisa desde o início, para se conhecerem melhor e ganharem eficiência, especialmente na gestão de dados de pesquisa.
Nesse caso, o texto fala da figura dos data stewards, como um sistema de suporte ideal, mas pouco definido no momento e com um custo muito alto para os serviços de biblioteca das universidades francesas, relacionado à recomendação 5.
Para bibliotecas universitárias
9. Realizar uma pesquisa com os pesquisadores da instituição para identificar práticas e habilidades na gestão de dados de pesquisa. Sensibilizar os órgãos políticos sobre o gerenciamento de dados, encorajá-los a estender a política de ciência aberta aos dados de pesquisa.
10. Apoiar as publicações de acesso aberto com uma política documental, dedicando recursos crescentes aos custos envolvidos neste tipo de publicação (assinatura, APC…). Implemente um método de rastreamento e consolidação de despesas de publicação.
11. Maior envolvimento das bibliotecas na publicação de revistas e, sobretudo, experimentar e dar maior apoio à criação de revistas editadas por estudantes (especialmente doutorandos) como acompanhamento da formação activa em publicação científica. Detectar e promover a publicação de periódicos de dados e treinar e ajudar o pessoal de pesquisa na redação de artigos de dados de pesquisa (documentos de dados).
12. Sensibilizar e formar doutorandos e investigadores sobre os identificadores (pessoais, mas também para publicações e dados) e ajudá-los a obtê-los junto dos órgãos competentes. Treiná-los no gerenciamento de sua identidade digital.
Conceitos já mencionados na recomendação número 2. Deve-se levar em conta que, por decreto, na França, é obrigatória a formação de doutorandos em ética e integridade em pesquisa.
13. Revisão de indicadores e métricas específicas de acesso aberto e, em geral, de ciência aberta. De acordo com as práticas emergentes para avaliação de pesquisas. Adotar definições e procedimentos que possam ser estendidos a todos os centros. Treine a equipe sobre essas novas métricas.
O relatório estabelece que a bibliometria é uma competência pouco desenvolvida nas universidades e que deve ser estimulada.
Avaliação Sugiro a leitura se você deseja trabalhar em uma pesquisa semelhante em bibliotecas espanholas ou se deseja aplicar medidas para promover a ciência aberta nas bibliotecas universitárias. Em todo o caso, é claro que uma política, a nível nacional ou institucional, não resolve ou promove por si só a renovação de processos, competências de pessoal ou sinergias e colaborações chave dentro e fora da universidade ou do centro de investigação; Em todos os casos, deve ser acompanhado de ações específicas. 4
1 Você encontrará o documento disponível no site do Ministério, mas gostaria de destacar o portal Ouvrir la science , pois contém outros documentos específicos interessantes sobre o assunto em questão.
2 O relatório abrange o primeiro e o segundo Planos Nacionais de Ciência Aberta da França. Muito bem explicado por Ciro Llueca .
3 O relatório foi escrito em plena pandemia do COVID-19, onde o treinamento virtual era mais relevante do que nunca, e por isso é valorizado de forma tão positiva.